抓取豆瓣相册图片——Mathematica版
之前写了一篇利用Scrapy去豆瓣“盗图”的文章,然后昨晚研究了一下mathematica,发现,其实它也可以做。。。当然,不能跟专业的Scrapy比,但是没有配置Scrapy环境或者懒得去搞那么复杂的东西的少年们,可以试一下Mathematica,而且mathematica因为在字符串匹配上和Python有着莫大的差距,所以一定把网页源文件爬下来后,如果有复杂的字符串操作需求,搞不好Mathematica会更强大。。但是,再说一句,这个不是专业的。。。
我们依旧以《海女》为例【顺便祭奠一下我那篇跳票了一个月的影评。。。】,首先分析网页源文件,在这之前,你要获得源文件,Mathematica有两种方法,一个是Import导入html,一个是URLFetch,但是我试了一下,两个都不怎么好使,其中Import导入的html会帮你排好版,但是排好版有什么用?而且图片的信息全部丢了,而后者URLFetch返回的就是原封不动的纯文本源代码,但是SCrapy的经验是,我们需要一个类似XPath一样的树状结构,搜了一下,Mathematica有一种变量XMLElement,他就是可以结构化源文件的东西,要怎么获得呢?嗯,还是Import,但是用XMLObject转一下~ 
mathematica code
然后就是目标图片的URL,虽然之前Scrapy那里说过了,但是我还在再发一遍,每张图片缩略图的URL附近的结构是这样的:
 依旧,我们要找的是/li下面/div下面的/a下面的/img的src,所以Mathematica中应该这么写:
依旧,我们要找的是/li下面/div下面的/a下面的/img的src,所以Mathematica中应该这么写:

mathematica code
这里需要说明以下的是代码里面大量的”___”通配号,原因是啥呢?这就是Mathematica里面一个XML神烦的地方,他会把换行符n,空格等东西悉数保存下来,也就是说,如果你没考虑到这些东西的话,那么匹配一般都会失败,不信的话可以以输入模式看一下Import返回来的东西,一般都是:
 虽然也可以在生成XMLElement之前先用URLFetch获取纯文本,然后用StringReplace替换掉,再转成XMLElement~不过比较繁琐而已。。
虽然也可以在生成XMLElement之前先用URLFetch获取纯文本,然后用StringReplace替换掉,再转成XMLElement~不过比较繁琐而已。。
回到正题,下一步就是根据之前Scrapy那篇所说,要获得原始图片,只要把URL中的thumb换成raw就可以了!!还是一个StringReplace解决: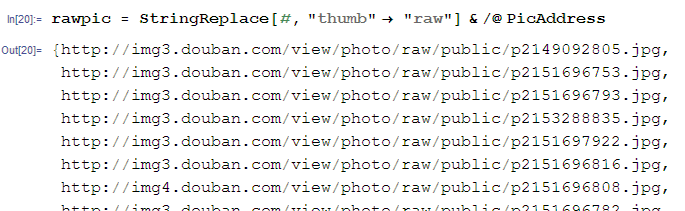
最后要输出[下载]的话,就是一个Export啦~也可以用Import看看获取的结果:【Mathematica会把图片转小,但是Export输出的话还是原尺寸的!!】
上面说了半天说的还是获取一个页面下的图片,为了实现“爬虫”,我们需要获得下一页的地址,还是查看源文件,下一页那些链接是这样子的:
 所以假设获取第二页的地址,那么就是:
所以假设获取第二页的地址,那么就是:
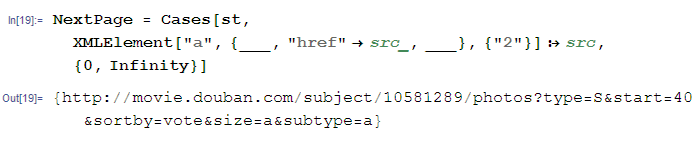
mathematica code
所以!!最后,我们可以写出这样一个API来实现递归,其实就是把上面的代码放到一起,然后加一个变量标记当前是第几页,以方便查找到下一页而已:

mathematica code
【完】
本文内容遵从CC版权协议,转载请注明出自http://www.kylen314.com

這文章沒人頂?
博客搬家之前的文章都没什么人看。。而且周围友邻的话Mma使用者不多
好东西好东西,最近想研究下怎么用mathematica抓取学校教室排布情况,从这篇文章里学到了很多
这么可爱肯定是男孩纸
复制下来试了试,结果发现现在只有登录才能查看大图了。衰~~