性别识别专题一——PCA
翻了一下之前Algorithm的最后一篇,居然是去年12月写的伪逆法,现在五月4号,也就是说我整整有半年没写关于算法的文章了,看了一下各个Category的数目,也属Algorithm最少,为了平衡这一问题,我决定出个长篇专题,里面涉及几个分布的小算法,最近就把这么几篇补上,这样就显得我不是没在搞算法的!!
好吧,就闲话到这,这次说的是PCA算法,PCA的全称是主成分分析法(Principal Component Analysis),它一般是用于模式识别等算法中的预处理模块,做什么用的呢,一般两个方面,一个是对数据进行降噪处理,另一个就是在模式识别中对数据进行降维。什么意思?比如说吧,我这个专题是性别识别,用的是不同性别的人脸图像,图像的像素数就是原始的信息数据,假设一幅图像时640*480,那么相当于一幅图像的特征向量是640*480=307200维,这个维数显然是很可怕的,所以需要降维,怎么将呢?就是找出这些维数里面可以作为区分的那些维,把他们提取出来,剩下的扔掉就可以了。
那么要怎么找出这些所谓的有用的维数呢?我们想想,一般所谓的没用的维数,无非是指两个方面,一个是这一维在所有的数据里面都是差不多的,换言之,噪声,假设上面307200维中有些维数完全就是像噪声一样分布,那么我们称这一维就是不带有什么信息量的,对吧,那么这一维去掉就可以了。然后第二方面,相关性,假设某一维和另一维呈正相关或者负相关,反正就是相关系数的绝对值很接近于1,那么这两维我们只要取其中一位就是了,对吧。
那要怎么做到处理上面所说的两个方面呢?我们知道,上面所说的其实就是两个东西,一个是各个维度之间的相关性,以及维度自身所有数据之间的方差,那么什么东西可以同时得到这两个呢?协方差矩阵,没错,就是你了!!
首先我们来说一说PCA的具体做法,首先假设我们有N个样本,每个样本的维数的R,我们需要计算出平均样本,也就是所有样本相加,然后除以N,得到一个平均样本D,它的维数自然是R×1,接下来我们计算每个样本与这个平均样本D的差,每个差显然也是R×1的向量,之后呢,把这N个差向量拼成一个R*N的样本集向量X,在理解上,我们只是把所有样本都减去了同一个数而已,所以这个新的X也应该可以表征原本的所有样本数据,也就是说数据信息没有变。
但是,并不仅仅是这样,对于那些我们刚刚所说的第一个方面的无用数据,它们所在的位置差不多就是变成了以零为均值上下浮动的噪声了,因为减去了均值嘛。
接下来我们计算这个样本集X的协方差矩阵,Q = X×XT,维数是R×R,协方差矩阵主对角线上的元素就是每一位自身的方差,其他位置的元素就是不同维度之间的相关系数。
对于我们的最终目的,降维,或者说降噪,我们希望得到怎么样的一个结果呢?答案应该是一个只有主对角线上的元素非零,其余未知的元素都是零,这代表什么,这样表示维度之间的相关性最小。要怎么做到这个呢?自然就是矩阵对角化,得到一个对角化的矩阵,怎么对角化,看线代的书去,其实这里我们也不关心怎么得到对角化矩阵;因为我们知道,对角化之后对角线上的元素是什么?没错,就是原来那个矩阵(其实准确说应该是方阵)的特征值,这个概念很重要,是PCA的核心。这里说一句吧,怎么得到对角化矩阵,其实就是原来的矩阵左乘特征向量矩阵的倒置再右乘特征向量矩阵,这里的左乘和右乘我们可以成为对原来矩阵Q的一个操作,或者叫变换,变换就得到一个对角矩阵了,对角线上的元素(原来矩阵的特征值)的大小表示的就是这个维度的能量,当然现在这个对角矩阵的第k维肯定不是原来的第k维的大小了,但是我们不管,因为我们知道现在经过这一个变换之后我们得到的那个对角矩阵相关性最小,而且,我们可以挑出特征值最大的那些维度来作为含信息量大的维数。因为原矩阵Q是R×R的,共有R个特征值,那么我们挑出最大的一部分,肯定小于R个,这样就实现了降维。
经过上面的分析,我们就可以得出PCA核心的算法步骤,上面那段看的模模糊糊的孩纸们,可以对照着下面的步骤来理解。
首先,我们得到了Q了,然后计算出Q的特征值和特征向量,我们挑出最大的一部分特征值和它们对应的特征向量,假设有p个,把这些向量R×1维的特征向量拼成一个R×p维的映射矩阵w,然后我们只要把原来的样本集矩阵X和这个w相乘,得到p*N的降维后的样本矩阵,也就是说现在的每个样本的维数是p,p必然小于R。
我总觉得好像没怎么说清楚,我在用另一个角度解释一遍吧,首先,我们得到了Q,然后计算出它的对角矩阵,对角矩阵主对角线上以外的元素为零,说明什么,说明我们把原本的向量映射到了一个新的坐标系中,在这个坐标系中,不同维度之间是正交的(因为非主对角线元素为0),而我们是怎么把原来的向量映射过来的呢?就是原来的向量乘了那个特征向量所组成的矩阵。我们得到新的这个空间中,还是R维,每个向量不同纬度之间是正交的,但是每个维度的数值是不一样的,有些大有些小,形象点讲就好像我们把原来的一个奇怪的三维空间中的数据一一映射到一个三维的标准的xyz坐标系中,x的值怎么算?就是原向量点乘第一个特征向量,y怎么算,就是原向量点乘第二个特征向量,z就是点乘了第三个特征向量,但是映射过来之后,我们发现x这一维的数都很小,而yz的数则比较大,就是说所有样本映射之后都集中在yz平面里面,那么就是说x这一维信息量不大,因为都很小不便于区分不同的向量。这样懂了么?我们知道对角矩阵上的对角元素,也就是特征值,代表的是映射后这一维的能量的大小,点乘这个特征值对应的特征向量,我们就可以得到这一维的数值,但是如果既然我们知道某一维的能量不大,我们就不需要点乘这一维的特征向量了,所以我们一开始就挑出特征值大的那些维对应的特征向量来,上面我们举的xyz的例子,我们只要挑出y和z对应的特征值对应的特征向量,然后这两个特征向量拼成一个2×R的映射矩阵,原向量R×1乘以映射矩阵之后就得到一个1×2的向量,这就是yz两维的值,这就实现了降维。
讲到这里如果还不怎么懂我就真没办法了。。。
反正下面是一个例子,半天没想到好例子,就搞了一个很极端的例子,我们假设特征向量是16维,然后有100个正样本和100个负样本,每个样本16维画出来如下所示:

假设蓝色是正样本,红色是负样本,可以看得出来,前五维正样本的数在100以上,负样本在100以下,再看看10到16维,正好相反,而其余的6到9维正负样本都在100附近,按照我们上面的理论,6到9维属于噪声,无法用于分辨两个样本,但是剩下的12维又怎么样呢?都是有用的么?显然不是,剩下的12维里面,真正有用的,只有一维,你想想他们的相关系数就知道了。
计算的结果呢,特征向量是: 9.6872 0.0580 0.0528 0.0480 0.0447 0.0423 0.0384 0.0374 0.0354 0.0334 0.0313 0.0306 0.0292 0.0259 0.0226 0.0205
看到了么,只有一个特征值特别的大,其余的都很小,说明真正有用的只有一维,我们取出这一维的特征向量W,然后把X和W相乘,每个样本原来16维,现在都变成了1维,这数据量可谓是大大减小了,因为正好是1维,我们画出正负样本(各100个)的曲线:
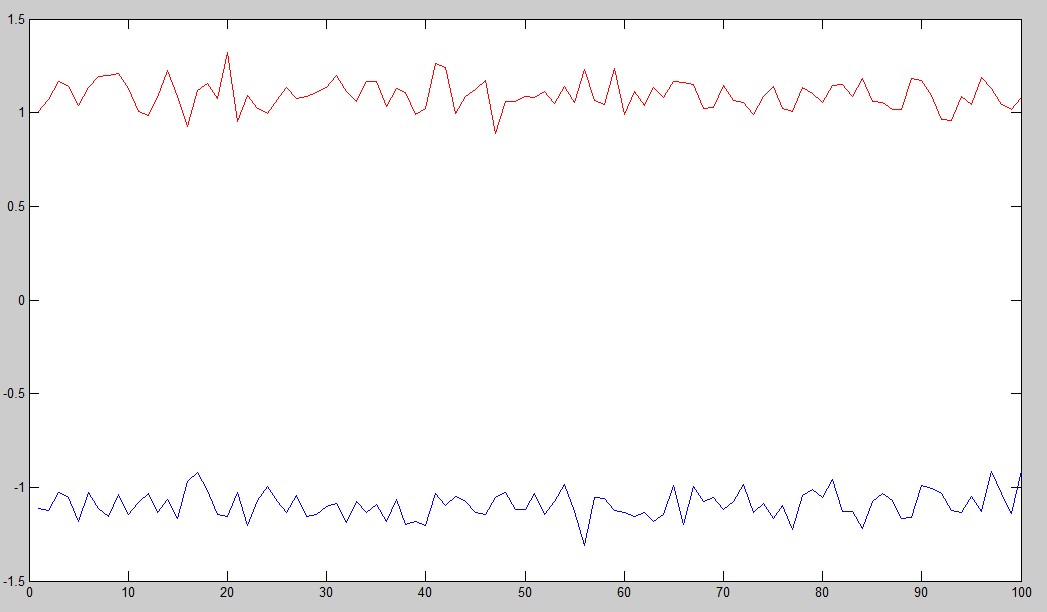
怎么样,看到了么?正负样本分别被映射到1和-1附近,这样子来区分他们就很简单了是吧。
这只是一个简单的例子,很极端。但是,实际上一般是几十万维变成几千或者几百或者几十维。
上面这个例子的代码老规矩,在文章的最后。
最后再说一丁点吧,就是上面提到的降噪是什么意思?我们文章里一直在讨论的是降维降维,降噪是什么呢?就是我们不是只取出p(p<R)个特征向量,而是全部取出,也就是说R维映射之后还是R维,但是新的R维的信噪比会高于原来的R维的数据,以上!!
Code:
function PCA_Demo()
clc;
close all;
[Pos Neg] = CreateDataSet(16,[1:5],[6:9],[10:16],100);
All_Sample= [Pos',Neg'];
Avg = mean(All_Sample')';
Dif_X = All_Sample - repmat(Avg,1,size(All_Sample,2));
w = PCA(Dif_X);%%得到投影向量
R = w'*Dif_X;
% plot(R(1:100),'r');
% hold on;
% plot(R(101:200),'b');
function eig_vector = PCA(Dif_X)
Q = Dif_X*Dif_X';
[eig_vector eig_value] = eig(Q);
eig_value = fliplr(abs(diag(eig_value)'));
eig_thre = 0.9;
eig_value_cum = cumsum(eig_value)/sum(eig_value);
L = find(eig_value_cum >= eig_thre);
L = L(1);
eig_vector = fliplr(eig_vector);
eig_vector = eig_vector(:,1:L)./repmat(sqrt(eig_value'),L,1);
function [Pos Neg] = CreateDataSet(All_Dimension, ...
Pos_Dimension, ...
Noise_Dimension, ...
Neg_Dimension, ...
Sample_Num)
Avg_Level = 100;
Diff = 20;
Perturbation = 15;
Pos = zeros(Sample_Num,All_Dimension);
Neg = zeros(Sample_Num,All_Dimension);
Pos(:,Pos_Dimension) = ...
Avg_Level-Diff+rand(Sample_Num,length(Pos_Dimension))*Perturbation;
Pos(:,Neg_Dimension) = ...
Avg_Level+Diff+rand(Sample_Num,length(Neg_Dimension))*Perturbation;
Neg(:,Pos_Dimension) = ...
Avg_Level+Diff+rand(Sample_Num,length(Pos_Dimension))*Perturbation;
Neg(:,Neg_Dimension) = ...
Avg_Level-Diff+rand(Sample_Num,length(Neg_Dimension))*Perturbation;
Pos(:,Noise_Dimension) = ...
Avg_Level + rand(Sample_Num,length(Noise_Dimension))*Perturbation;
Neg(:,Noise_Dimension) = ...
Avg_Level + rand(Sample_Num,length(Noise_Dimension))*Perturbation;
%% Draw Data Set
% figure;
% for i = 1 : Sample_Num
% plot(Pos(i,:),'r');
% hold on;
% plot(Neg(i,:),'b');
% end
【完】
本文内容遵从CC版权协议,转载请注明出自http://www.kylen314.com
