近邻传播聚类Affinity Propagation
机器学习中一个很重要的方面就是聚类算法。聚类算法说白了就是给你一大堆点的坐标(维度可以是很高的),然后给你一个距离度量的准则(比如欧拉距离,马氏距离什么的),然后你要自动把相近的点放在一个集合里面,归为一类。
继续科普:一个比较传统的聚类算法就是k-Means聚类,算法很简单,哦,说起这件事,我刚刚在整理东西时就发现了一篇讲到k-Means的论文,里面又是一大堆看不懂的符号,我说你们真的有必要那么装逼么??
比如说下面这幅图,有这么多个点,我们强大的大脑可以瞬间分辨出这里有三个团簇,一般术语叫cluster。
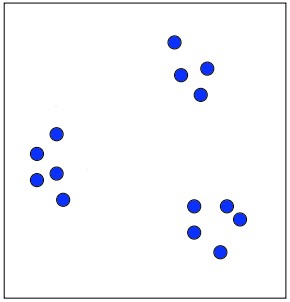 但是K-Means算法是怎么实现的呢?
但是K-Means算法是怎么实现的呢?
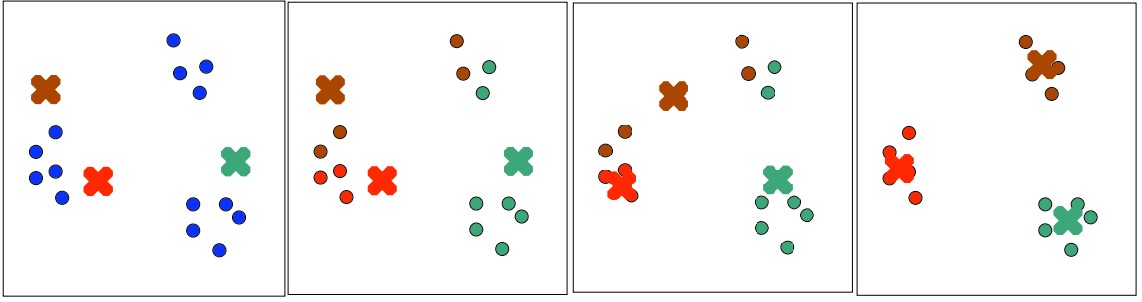
首先我们已经知道有三个类了,所以呢就随机的选三个点(上图最左),作为三个类的中心,也可以叫做代表点,之后呢把图中所有的点归于离他最近的那个点,认为这个点就是属于这一类(上图左二),显然这样分类是不行的,然后我们计算每个类的那些点的中心(或者称为重心),把每个类的代表点的位置移到这个类的重心处(上图右二),然后再把全图中所有点都归于他们最近的那个类代表点,这时有些点的归属就会发生变化,然后不断的这么迭代,知道所有点的归属都不再变化为止,我们就认为这个算法收敛了。
显然这个算法很简单,比较简陋,但是大部分情况下都很实用!!要说缺点的话,第一,我们必须先知道总共有多少个类,其次就是算法最后能否收敛和收敛的速度对开始随机挑的那几个点很敏感。
好吧,扯远了,我这篇博文不是为了讲K-Means的,想介绍的是近邻传播聚类算法。
近邻传播,英文是affinity propagation,它是一种半监督聚类算法。比起传统的像K-Means,它有很多别的算法所望尘莫及的优势,比如不需事先指定类的个数,对初值的选取不敏感,对距离矩阵的对称性没要求等。
AP聚类算法是将每个数据看成图中的一个节点,迭代的过程即是在图中通过传播信息来找到聚类集合。本文计算两个数据点的相似度采用距离的负数,也就是说距离越近,相似度越大。相似矩阵S中i到j的相似度就是刚刚所说的距离的负数。但是主对角线上的那些数表示的是某个点和自身的相似度,但是这里我们不能直接用0来表示。根据算法要求,主对角线上的值s(k,k)一般称为偏向参数,一般情况下对所有k,s(k,k)都相等,取非主对角线上的所有数的中位数。这个值很重要,他的大小与最后得到的类的数目有关,一般而言这个数越大,得到的类的数目就越多。
这里为什么要设定一个偏向参数而不直接用0来算呢,估计是因为AP聚类算法是要用图论的一些东西来理解的,它把所有的点都看成一个图中的节点,通过节点之间的信息传递来达到聚类的效果。具体比较复杂,形象一点说就是我告诉你我和这些人是死党,如果你认为你也是我死党的话,那你就加入我们这一堆人里面来吧!
有一些详细的原理上的东西就不说了,直接说计算过程吧。。聚类就是个不断迭代的过程,迭代的过程主要更新两个矩阵,代表(Responsibility)矩阵R = [r(i,k)]N×N和适选(Availabilities)矩阵A=[a(i,k)]N×N。 这两个矩阵才初始化为0,N是所有样本的数目。r(i,k)表示第k个样本适合作为第i个样本的类代表点的代表程度,a(i,k)表示第i个样本选择第k个样本作为类代表样本的适合程度。迭代更新公式如下:
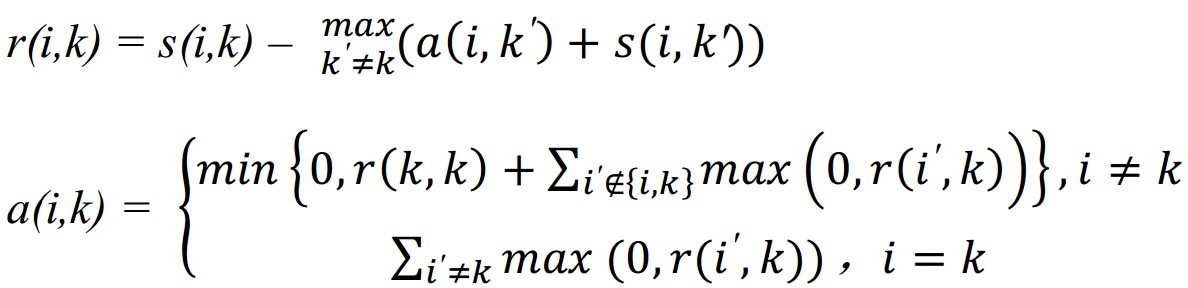 每次更新后就可以确定当前样本i的代表样本(exemplar)点k,k就是使{a(i,k)+r(i,k)}取得最大值的那个k,如果i=k的话,那么说明样本i就是自己这个cluster的类代表点,如果不是,那么说明i属于k所属的那个cluster。
每次更新后就可以确定当前样本i的代表样本(exemplar)点k,k就是使{a(i,k)+r(i,k)}取得最大值的那个k,如果i=k的话,那么说明样本i就是自己这个cluster的类代表点,如果不是,那么说明i属于k所属的那个cluster。
当然,迭代停止的条件就是所有的样本的所属都不在变化为止,或者迭代了n次都还没有变化(n的值可以自己取)。
说起来还有一种判断点属于属于哪一类的方法,就是找出所有决策矩阵主对角线元素{a(k,k)+r(k,k)}大于0的所有点,这些点全部都是类代表点,之后在决定其余的点属于这里面的一类。这两种方法的结果我没比较过诶,不知是不是一样的。
另外还有一点就是AP聚类算法迭代过程很容易产生震荡,所以一般每次迭代都加上一个阻尼系数λ:
rnew(i,k) = λ*rold(i,k) + (1-λ)*r(i,k)
anew(i,k) = λ*aold(i,k) + (1-λ)*a(i,k)
下图是采用下面的API画出来的聚类结果:

function idx = AP(S)
N = size(S,1);
A=zeros(N,N);
R=zeros(N,N); % Initialize messages
lam=0.9; % Set damping factor
same_time = -1;
for iter=1:10000
% Compute responsibilities
Rold=R;
AS=A+S;
[Y,I]=max(AS,[],2);
for i=1:N
AS(i,I(i))=-1000;
end
[Y2,I2]=max(AS,[],2);
R=S-repmat(Y,[1,N]);
for i=1:N
R(i,I(i))=S(i,I(i))-Y2(i);
end
R=(1-lam)*R+lam*Rold; % Dampen responsibilities
% Compute availabilities
Aold=A;
Rp=max(R,0);
for k=1:N
Rp(k,k)=R(k,k);
end
A=repmat(sum(Rp,1),[N,1])-Rp;
dA=diag(A);
A=min(A,0);
for k=1:N
A(k,k)=dA(k);
end;
A=(1-lam)*A+lam*Aold; % Dampen availabilities
if(same_time == -1)
E=R+A;
[tt idx_old] = max(E,[],2);
same_time = 0;
else
E=R+A;
[tt idx] = max(E,[],2);
if(sum(abs(idx_old-idx)) == 0)
same_time = same_time + 1;
if(same_time == 10)
iter
break;
end
end
idx_old = idx;
end
end
E=R+A;
[tt idx] = max(E,[],2);
% figure;
% for i=unique(idx)'
% ii=find(idx==i);
% h=plot(x(ii),y(ii),'o');
% hold on;
% col=rand(1,3);
% set(h,'Color',col,'MarkerFaceColor',col);
% xi1=x(i)*ones(size(ii)); xi2=y(i)*ones(size(ii));
% line([x(ii)',xi1]',[y(ii)',xi2]','Color',col);
% end;
【完】
本文内容遵从CC版权协议,转载请注明出自http://www.kylen314.com

您好,读了您的文章,有几个问题想请教您,能否加您的qq啊,或者加我的1833221563
额,你在下面留言吧,我好想看到你的留言看到太晚了,不知道你的疑问结局了没?
楼主您好,想问问,第二种判断点属于哪一类的方法即找出主对角线元素{a(k,k)+r(k,k)}大于0的所有点,这些点全部都是类代表点,这一种是为什么?不太理解,希望楼主能讲解讲解。
楼主大大,最近我再看AP算法,但是里面r(i,j)和a(i,j)的迭代原理实在是理解不能,能不能给我解释一下!
很好的东西奥