豆瓣爬虫杂记
手头上有一个便宜的VPS,一直没怎么用,除了用来跑程序和VPN外。然后最近觉得没什么程序在上面跑很对不起它,就没事找事地想让它去爬点东西,但是也没想到什么好爬的,就愉快地决定让它去爬一些豆瓣的信息;
初步计划先让它爬一下豆瓣的书的信息和豆瓣用户关注被关注的关系网;这里随便写一下爬虫的杂记,作为我最近的存在感。。。
豆瓣BOOK
豆瓣的书啊,电影啊,音乐啊那些条目有一点很讨厌,就是他们的URL的编排,都是这种形式的:
type可以是”book”,或者”music”或者”movie”;
但是id完全没有什么规律(大概没有吧),不仅仅是说你无法从id中判断出这个条目是书还是电影还是音乐;而且就算你要找书的URL,你也不知道这些id是服从什么规律的;比如id=10000可能是一本书,但是10001可能对应的type就变成了music,也有可能是404。。。
如果我想爬下都把上面所有的书,我从http://book.douban.com/subject/1/ 开始扫描起的话,预计会花上几个月的时间,得到很多404,而且不知道什么时候是个尽头。。【另外movie和music占了更多的id】
最后没办法,找了一下,决定从这个页面下手:
如下:

这些是热门的tag,但是好像不是全部,虽然觉得差不多了,估计不包含在这里面的都是一些冷门的书,热门的话基本一定会出现在这几百个tag里面的【大概。。】。
所以我的计划是,从每个标签爬进去,一页一页爬下书的id,构建一个列表,里面全是有效的书id,也只有id而已;而且可以顺便分好类,在一个文件里面记录下属于某个tag的所有书本的id;
这个文件我爬好了,放在github的BookId.txt文件中;
这个过程大概花费了6,7个小时,爬下来统计了一下,去重之后8万本不到,和网上传说的10万本比,少了一些,但是估计热门书籍都没漏(吧)。。
代码
最后爬取书的详细内容的时候再去抓取别的信息。
有了书本ID,我开始还准备傻傻地去爬下每个http://book.douban.com/subject/[id]/ 的页面源码的,但是发现豆瓣开放了API V2,翻看了一下图书的API V2,发现只要请求:
就可以返回书本信息的json;
这个过程大概vps爬了一周,一边爬一边写到文件里面以便后期分析(其实主要是为了防止中途崩溃可以断点续“爬”);
主要爬取了书的名字,评分,评分人数,出版社,价钱,页数,出版时间这几个信息;
放在了github的book_detail.txt里面,如果有人想自行分析,可以拿去研究研究。。【我猜没有】
代码
然后用Mathematica写了几行代码分析了一下评分分布(去掉0分的后),嗯。。挺合理的:
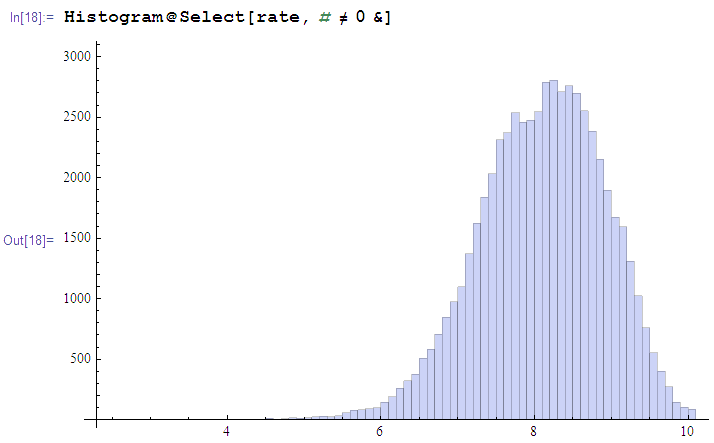
之后找了一下评分大于⑨分,评价人数大于1000的那些书:
bestbook=
{name[[#]],rate[[#]],ratenum[[#]]}&/@Select[Range@n,rate[[#]]>9&&ratenum[[#]]>1000&];
SortBy[bestbook, #[[2]] &] // Reverse // Column

壮哉大灌篮,可能有人觉得评价人数才1000出头,不具备代表性;
下面这个列表是分数大于⑨,评价人数大于10000的书,有几本我最近想看一下了。。
- {灌篮高手(31),9.5,25388}
- {红楼梦,9.5,88089}
- {海贼王,9.5,23581}
- {史记,9.5,10742}
- {机器猫哆啦A梦23,9.4,27123}
- {1984,9.3,10890}
- {1984,9.3,10076}
- {冰与火之歌(卷一),9.3,16767}
- {撒哈拉的故事,9.3,12019}
- {撒哈拉的故事,9.3,10855}
- {撒哈拉的故事,9.3,10613}
- {飘(上下),9.3,61462}
- {一九八四,9.3,17514}
- {活着,9.3,13208}
- {一九八四·动物农场,9.2,21619}
- {七龍珠 34,9.2,21676}
- {子不语3,9.2,11463}
- {福尔摩斯探案全集(上中下),9.2,42553}
- {三国演义(全二册),9.2,47330}
- {撒哈拉的故事,9.2,32557}
- {百年孤独,9.2,42867}
- {动物农场,9.2,21107}
- {小王子,9.2,10321}
- {三体Ⅲ,9.2,38614}
- {三体Ⅱ,9.2,37147}
- {NANA(1-13),9.1,15788}
- {明朝那些事儿(1-9),9.1,23841}
- {子不语(1,2),9.1,14904}
- {機器娃娃(1),9.1,10684}
- {小王子(中英文对照本),9.1,10163}
- {平凡的世界(全三部),9.1,70350}
- {经济学原理(上下),9.1,10032}
- {天龙八部(全五册),9.1,45739}
- {安徒生童话故事集,9.1,31924}
- {中国历代政治得失,9.1,16435}
- {肖申克的救赎,9.1,28744}
- {父与子全集,9.1,14587}
- {动物庄园,9.1,11173}
- {小王子,9.1,10024}
- {活着,9.1,92948}
- {活着,9.1,64119}
- {围城,9.1,12139}
豆瓣登陆验证码
在爬用户关注关系的时候遇到的第一个问题就是模拟登陆,有人说模拟登陆很简单啊:
loginurl = 'https://www.douban.com/accounts/login'
cookie = cookielib.CookieJar()
opener =
urllib2.build_opener(urllib2.HTTPCookieProcessor(cookie))
params = {
"form_email":EMAIL,
"form_password":PASSWORD,
"source":"index_nav"
}
response=opener.open(loginurl, urllib.urlencode(params))
但是,豆瓣比较麻烦的一点是,短时间内登陆几次左右你再登陆,就要你输入验证码了。。
![]()
一开始我觉得没什么办法,然后就正则表达式检测是否有验证码,如果检测到了,就手动保存到本地,然后等待用户识别输入,但是这样在VPS上弄很麻烦的样子,要开ftp软件把图片拿回本地看一下才可以。。
然后呢?前几天看知道宇创的技能表的时候,在很下面看到了:
…
验证码破解
- pytesser
…
然后就去谷歌了一下这货,发现,诶,好像很不错的样子诶,虽然是一个用于OCR的项目,但是google自动补全的关键字有验证码诶,而且不少人都是用它来做验证码的,我还以为捡到好东西了。。。然后看了一下自带的demo,它识别的是这个:

然后找了一下别人用它来做验证码识别的,比如。。。。。
![]()
![]()
![]()
识别你奶奶个腿啊,你敢不敢背景复杂点?!
然后我查了一下,也自己试了一下,这个pytesser工具还真是太他喵的大爷了。。你必须要把图片处理到非常非常干净,一丝半点噪声都没有,它才会好好工作。。
比如说我处理成这个样子了:
![]()
识别出来的结果还是错的,因为只要是一小点,它就会觉得,哦,这个可以是,或者.或者:或者\之类的;而且会被识别成哪个完全不知道,完全看大爷它的心情。。它甚至无视位置,在奇怪的位置出现的噪点它会理解成多行文本。。
但是有什么办法,想要自动识别,就(暂时)只能借助这个了。。
爬了一些验证码图片下来,发现豆娘的还不算太坑,主字体都是黑色的(这点最重要),而且英文笔画宽度大概有3~6个像素左右,背景是简单的带有一点明暗变化和椒盐噪声(黑白噪声):

当然也有一些特别坑爹的。。。
![]()
想了半天,发现多想无益,动手测试一下才是王道。。。【注:pytesser这玩意儿依赖于PIL库】
首先先二值化,把黑色的部分拿出来,然后要去掉尽可能多的背景,但是一开始我算是自己把自己坑了,没想太多,直接把图片转成灰度图,准备一个阈值解决:
def Binarize(img,threshold):
img = img.convert('L')
table = [0]*threshold+[1]*(256-threshold)
return img.point(table,'1').convert('L')
这个问题我是很后来才注意到的,这个效果必然很差,原因在于我用的是系统自带的彩色图像转灰度图的函数Image.convert(‘L’),但是我真正想要的二值化效果是把黑色变成黑色,其他颜色变成白色,但是这个做法会把蓝色,红色也变成黑色。。
比如之前的那个验证码
![]()
就会变成:
![]()
很无奈,还是乖乖写一个二值化函数吧,要让RGB三个通道的灰度值都小于阈值才行:
def Binarize(img,threshold):
img_G = Image.new('L',img.size,1)
w,d = img.size
imgdata,graydata = img.load(),img_G.load()
for x in range(w):
for y in range(d):
graydata[x,y] = 255*(imgdata[x,y][0]>threshold or
imgdata[x,y][1]>threshold or
imgdata[x,y][2]>threshold)
return img_G
这时候就变成了:
![]()
其中操作的时候虽然这些黑色的文字像素值都在(10,10,10)附近,但是不敢把阈值设太低,虽然这么做可以进一步去除噪点,但是同时会带来麻烦;一来阈值太低会把字符笔画变得更细;二来,容易出现断点,要是把w变成了vv,pytesser这货肯定识别不了。。【唉,感觉用pytesser就像在照顾熊孩子一样。。】
二值化是为了下一步,之后只要消除掉噪点,变成这个就行了:
![]()
去噪点是在不把笔画变细或者弄断的前提下进行的,所以自带的那些图形滤波函数我就不敢用了,首先我不清楚内部的变换核函数是高斯还是什么的(懒得看源码),虽然这并不重要。。最重要的是这种滤波方式绝对绝对会把笔画变细的;【显然的嘛,低通必然带来模糊化,而二值图模糊化的后果就是少的那部分(黑色)更少。】
以前用OPENCV做图像处理的时候,对于这种去噪,想都不用想,就是形态学处理一下马上就可以了,腐蚀一下然后再膨胀一下!
但是。。。我翻遍了PIL的函数库和GOOGLE了半天,愣是没有找到这两个函数。。【想了想,以后python还是不用PIL了,乖乖回去用OPENCV吧】
没办法,又不想自己实现(虽然实现并不难,有空写一个),但是我想到了另一个更简单的方法,直接直接查找每个黑色块的连通区域面积,把面积小于某个值的全部去掉就是了:
#返回跟(x,y)连通的黑色区域的每个点的坐标
def scrap_img(imgdata,dst,width,heigth,x,y):
findlist = []
waitlist = [(x,y)]
while waitlist != []:
cur = waitlist.pop(0)
for (i,j) in [(cur[0]+1,cur[1]),
(cur[0]-1,cur[1]),
(cur[0],cur[1]+1),
(cur[0],cur[1]-1)]:
if i < 0 or i>=width or j<0 or j>=heigth:
continue
if imgdata[i,j] == dst:
if not (i,j) in findlist:
findlist.append((i,j));
if not (i,j) in waitlist:
waitlist.append((i,j));
return findlist
def m_filter(img):
imgdata = img.load()
w,h = img.size
for x in range(w):
for y in range(h):
if imgdata[x,y] == 0:
scraplist = scrap_img(imgdata,0,w,h,x,y);
for p in scraplist:
imgdata[p[0],p[1]] =
255 - 254* (len(scraplist) > 30)
imgdata[x,y] = 255 - 254*(len(scraplist)>30)
其中上面第28-29行用了个小伎俩,对于每一个黑点(像素值为0),找到连通区域后,如果连通区域像素点少于特定的值,那么直接在原图中把这些点变成白色(像素值为255),否则变成1,这样就直接省掉一个变量,而且避免重复计算。
总结起来步骤就是:

处理到这个份上,大爷它表示总算可以识别了。。
不过这种方法太过简单粗暴了,识别率其实很低,但是不要紧,我们的目的不是要做一个高识别率的验证码破解程序,而是成功登陆豆瓣,只要识别成功一次就可以了,所以我们可以一个While语句不断地尝试,识别成功就可以了;
最后自动登陆代码就变成这个样子。。。
def logindouban():
loginurl = 'https://www.douban.com/accounts/login'
cookie = cookielib.CookieJar()
opener =
urllib2.build_opener(urllib2.HTTPCookieProcessor(cookie))
params = {
"form_email":EMAIL,
"form_password":PASSWORD,
"source":"index_nav"
}
response=opener.open(loginurl, urllib.urlencode(params))
html = ''
if response.geturl() ==
"https://www.douban.com/accounts/login":
html=response.read()
#如果需要验证码
imgurl=re.search('<img id="captcha_image" src="(.+?)"
alt="captcha" class="captcha_image"/>',html)
while imgurl:
url = imgurl.group(1)
urllib.urlretrieve(url, 'captcha.jpg')
captcha = re.search('<input type="hidden"
name="captcha-id" value="(.+?)"/>' ,html)
if captcha:
params["captcha-solution"] =
captchaRecognition.recognition('./captcha.jpg');
params["captcha-id"] = captcha.group(1)
params["user_login"] = "登录"
response =
opener.open(loginurl, urllib.urlencode(params))
if response.geturl() == 'http://www.douban.com/':
break
else:
response=
opener.open(loginurl,urllib.urlencode(params))
html=response.read()
imgurl=re.search('<img id="captcha_image"
src="(.+?)" alt="captcha"
class="captcha_image"/>', html)
return opener
效率还好,登陆只要两三秒就可以了。。
嘛,用户关系网还没开始爬(豆瓣用户数和书的数目可不是一个数量级的),大概。。这篇博文就先这样吧。。
后话:什么时候等我突破了迅雷娘的那个验证码,之前那个URL获取器就可以变成全自动了!!!
不过这个看起来好像很麻烦的样子。。还是有空自己搞一个模式识别的方法吧。。桌上一直放着本这方面的书没怎么看。。

【完】
本文内容遵从CC版权协议,转载请注明出自http://www.kylen314.com

“其中上面第28-29行用了个小伎俩,对于每一个黑点(像素值为0),找到连通区域后,如果连通区域像素点少于特定的值,那么直接在原图中把这些点变成白色(像素值为255),否则变成1,这样就直接省掉一个变量,而且避免重复计算。”这个feature好赞,上次kanggle rush题目的时候居然没想到这个…
开始那个二值化之后只有0,1的值我也没想到,后来发现重复计算了,才把二值图转会灰度图。。kanggle rush是个啥?
kanggle 拼错了… kaggle 是名词,rush是动词,http://www.kaggle.com/competitions << 这个
好像很有意思的样子!!MARK
training data 的data set大多比较小,普通的knn,perceptron 有时候base line都达不到的学渣常常不得不动用deep learning来作弊
之前阿里的大数据比赛给的样本也极其之少,导致后来出现了各种奇葩的算法,而那些很成熟的算法全都用不上。。
实际上想知道……用爬虫抓取豆瓣之后……打算做个索引么啊,不行了,最近撸多了,头痛
索引有意义么?想要查特定信息的话上豆瓣不就可以了。。注意身体。。
评分不考虑出版时间么……
其实我已开始存储那些信息就是为了做一个全面一点的分析,但是价格,页数,出版时间那些格式太乱了,要写一个鲁棒性很强的正则表达式很麻烦的样子。。
牛X的人物~
迅雷这个验证码找到开始和结束位置,然后等间隔分割,扔到神经网络或者svm里可能可以吧,不过目测识别率能过50%就不错了…如果字数和大小都是随机的…嗯,应该无解了…
基于学习的方法的前提都是要有很好的分割预处理,这个麻烦在于一条和文字等粗同色的线把目标连在一起了。。分割就极度困难了。。而且字还有正负倾角。。
碉堡了。小白看着第一次觉得这个特么有意思,哈哈~
菊苣好厉害
别闹,我只是挑了好一点的结果来水博文我会乱说?
/w 菊苣就在乱说嗯。
大神。。膜拜啊
爬书那个没啥难度啊。。。验证码那个识别率不高啊。。
那堆9分以上10000评的书里只对《安徒生童话故事集》有兴趣怎么破。。。
上面我最想补的是《三体》
只看过第一部= =,其实窝倒不是很喜欢。。。更喜欢魔法是为什么。。。
今天实验室一个师弟说,他比起海贼王更喜欢妖尾,因为妖尾打斗是用魔法的。。。
哈哈,像超炮就很好,披着科学外衣,实际上是魔法,正合我口味。
可惜动画让我放弃了追小说的念头。。
小说是指魔禁么= =太多太长了根本没补的动力。。。
好吧,你说的是魔炮。。
红楼上榜了,但石头记遗迷却没有上榜
分数大于⑨评分人数大于10000的列表里面发现没有感兴趣的了果然偶只是一个普通人么_(:з」∠)_
对那些大部分都有兴趣的不是普通人,对极少少部分有兴趣或者都没兴趣的才是普通人。。
进来看下,主题不错
英語考差了,過來看菊苣的post,感覺迅雷的驗證碼果然坑爹。#多說那麽登陸啊。。。?
我这post让you想起了your English test考的not good是因为post里面有english words的reason么?233333迅雷验证码这个我至今没想到好算法解决它。。。不想弄了。。多说什么?
pytesser是python版本的tesseract?
是的,但是实践表明不好用。。。
有没有java可以用到的类似pytesser的工具
不是很了解java,你可以在github上面搜一下“java ocr”看看
你的这个方法也不太好使吗
这个方法的话识别率也不是很高。。主要是这个工具包它对图像质量要求太高了。。
那你这个方法平均多长时间可以登录上呢,一个账号登陆上之后能爬多久,登录上之后就可以一直爬了吗,应该不可能吧
几秒就可以吧。登录上去基本可以一直爬的,除非那边判定你是机器人,把你禁了。我这个验证码纯粹是为了研究一下pytesser而已,真要爬的话,可以直接尝试将图片读下来人工识别,然后输入验证码,在或者可以看看豆瓣提供的第二版API,那个应该最方便。
我有试过人工识别验证码,爬了几个小时,cookie中关于[name: dbcl2][value: “89759172:PXGmZL66FZI”]的值就没有了,好像cookie过期了吧,我也不知道怎么回事,如果你这个方法可以识别验证码的话我想试试,几秒也不长
豆瓣cookie有这么短寿命么?如果真是这样,确实需要自动登录。。你有试过API登录么?
没试过,我是想着能不用api就不用api
我说的不是别人封装好的代码的api,而是向https://api.douban.com/v2/***发get/post请求来达到正则解析页面源码的那种目的。
是豆瓣提供的API是吧,说的就是那个,你模拟登陆之后可以一直爬?
当时研究这个只是为了测试pytesser,之后没测试爬取的东西。。
像素点(0,0)是左下角还是左上角,不要嫌我问题白痴,我是真不知道
你那个二值化的时候threshold设的是多大
左上,阈值45
连通区域像素个数是30吗
代码里写的是30,不过这个不是很要紧啦。。话说这篇博文活生生被评论盖出一层高楼来了。。
这个不要紧吗,那个不是过滤小的连通域的阈值吗,要不你给我个方式私聊呗,我先给你说我扣扣号619422869
盖楼是个好事情
盖楼狂人你好
不谢不谢
这个破解验证码的思路和我好像,最主要的是去除了背景,文字它还是随机扭曲的。后来我就放弃折腾啦,还是你的完成度高。
豆瓣这个还不算折腾。。迅雷那个才叫折腾。。
恩,我觉得豆瓣的验证码算很友好的了,所以才想折腾下,不过我毕业太久,图像处理那些东东都忘啦(其实一直很渣),也是想直接用pytesser。
从头看到尾,结果我想看的用户关系识别被你一笔带过了。好坑啊
我都忘了我还没分析那个东西了。。。别在意了~
现在豆瓣的apikey申请链接失效了,难道逼着我去爬网页?
验证码那块很有启发 多谢!