爬取Zero动漫下载链接的几种方法
我总算发现了,我只有在想偷懒的时候才会变得很勤奋。。
ZERO动漫
这小标题看起来有点像软文啊!!其实真的不是啊!!
我一般看动画的方式,当它还在连载的时候,我就在B站上看,之后在它完结或者换季番的时候,我会选择一部分来收藏,其实虽说是收藏,更像是留着等“布教”用,在给那些不逛B站的人宣传某部动画之后可以马上拿出资源给他们,顺便拉其入坑!!
基于此,所以我一般移动硬盘里面放的也不是BD版本,就是普清版本,经过本科时的各种研究,我现在基本定下来在Zero动漫下载动画,虽然我也知道极影啊,动漫花园啊,还有天使动漫这些论坛之类的,而且我也分别有一段时间在这些地方下过,但是最后发现最常来的还是ZERO动漫,我也不怎么清楚为什么,可能是“找资源”这个过程是最省事的吧。。。毕竟一部动画就一个页面,而不像极影之类的搜一部动画可以找到各种字幕组的。。最后下下来发现是各种字幕组的大杂烩,虽然下载合集的话极影那些会比较方便~
好吧,扯远了,回到Zero动漫,作为迅雷党,一般有两个路径在Zero上找到资源:
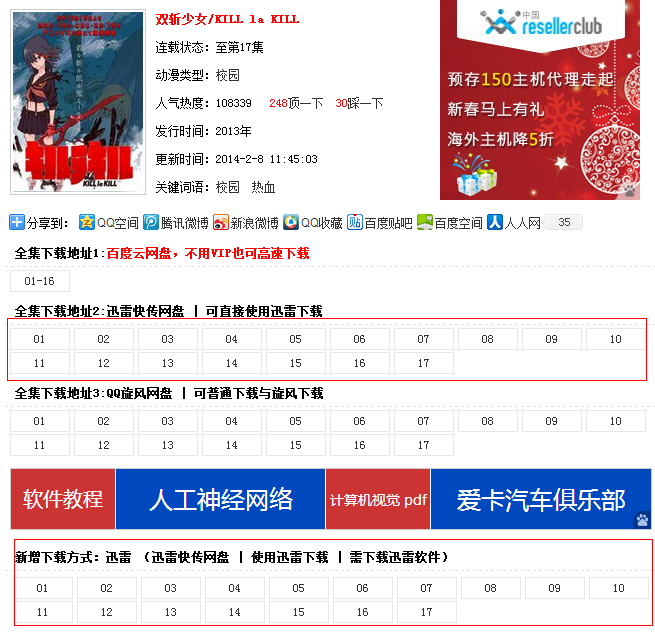
第一个是选择上图的第一个红框里面的东西,你点某一集它会弹出下面这种框: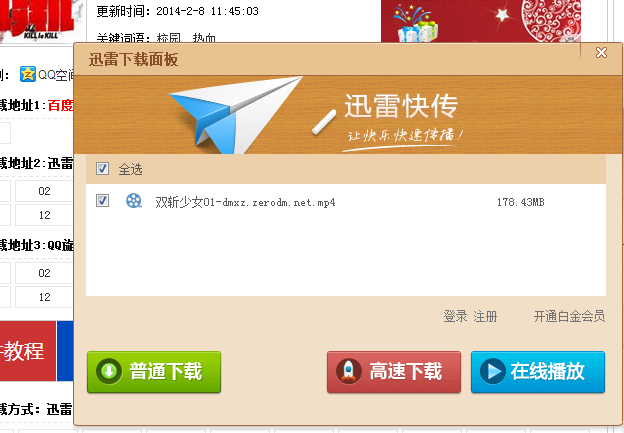
然后点击下载就可以了,但是我从来不用这个,因为这个框弹出来不是很快,而且就像这个页面的模态对话框一样,你每一时刻只能打开其中一个,所以效率上来讲是很慢的!!【但是事实上这上面那个按键对应的链接是迅雷的一个下载页面的URL,你查看一下源代码就知道了,所以估计是ZERO动漫自己JS文件弹出这个自以为很方便的下载窗口的。。】
另一个方法就是点击第二个红框,它会跳转到如下页面:
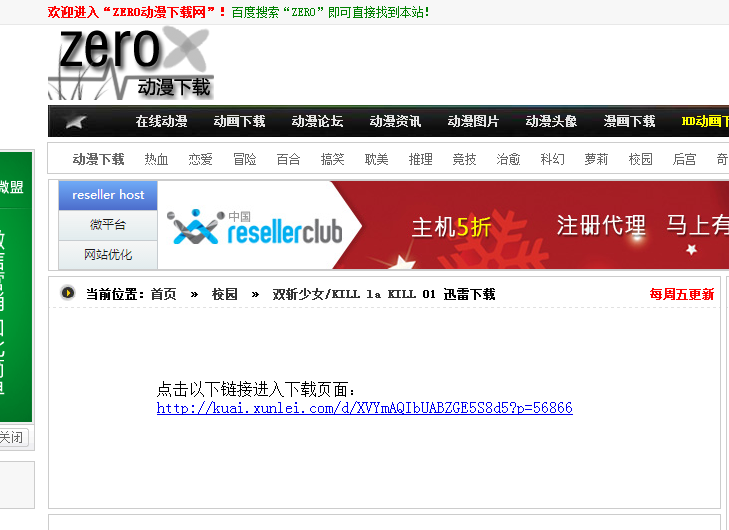
然后你点击它的链接,他才会跳转到下载界面:
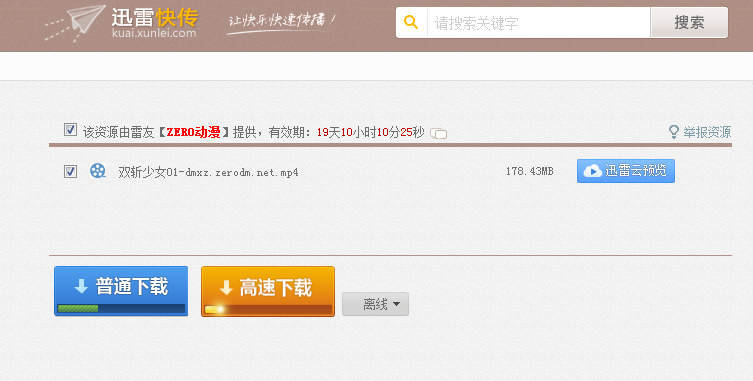
事实上这个真正的下载页面地址就是第一种方法链接的那个地址;
所以不管那种方法,感觉都是巨麻烦的,我以前一直用的方法就是按着CTRL,然后狂点第二种方法的链接。。。至少并行的要比第一种串行的要快,是吧~
考虑到以后经常还要这么来,为了一劳永逸,我就准备写一个可以在一开始的页面,自动一直爬啊爬,就把真正的下载链接给爬出来,放在一个文件里面,之后只要CTRL+C,CTRL+V到迅雷娘里面就可以了~
Scrapy法
说到爬虫了,我最先想到的方法就是Python的Scrapy,这也是手头上爬虫用起来最顺手的一个工具;
根据下载页面http://dmxz.zerodm.net/xiazai/XXXX.html的源码,可以看出下载链接就是在一个class为numlist的div下的ul下的li下的a的href里面,所以XPath就是//div[@class=’numlist’]/ul/li/a/@href,但是事实上这样找到会有一个干扰项的,没错,就是QQ旋风网盘的下载页面地址,要区分方法有两个,一个是上面的XPath节点应该有一个内容为“全集下载地址2:迅雷快传网盘 | 可直接使用迅雷下载”的叔父节点,而不是“全集下载地址3:QQ旋风网盘 | 可普通下载与旋风下载”,但是还有一个更简单的判断方法,判断一下链接里面是不是带有xunlei字样就可以了;
上面方法可以找到链接如http://kuai.xunlei.com/d/XVYmAQIPLwC1hqpS459?p=56866字样,然后再去爬这个页面就可以了,爬到Xpath节点是//ul//li//a[@class=’file_name’]/@href的链接形如:
http://dl2.t6.sendfile.vip.xunlei.com:8000/%5B%E5%8….
事实上这个并不是我们最后要的真正的下载链接URL,因为它实际上是一个向迅雷服务器请求URL的命令,但是不要紧,我们获得这个就可以了,因为把这个命令黏贴到迅雷的“新建任务”里面会自动变成URL的~
下面是Scrapy代码:
from scrapy.spider import BaseSpider
from scrapy.selector import HtmlXPathSelector
from scrapy.http import Request
from scrapy.conf import settings
import time
import sys
class DouBanImage(BaseSpider):
name = "zerodm"
#要下载的动画所在的Zerodm页面
start_urls = ["http://dmxz.zerodm.net/xiazai/2000.html",
"http://dmxz.zerodm.net/xiazai/2017.html"]
#延迟
download_delay = 1
#保存下载链接的文件
filename = 'download_url.txt'
f = open(filename,"wb")
def parse(self, response):
req = []
hxs = HtmlXPathSelector(response)
#找到资源链接所在的页面
urls =
hxs.select("//div[@class='numlist']/ul/li/a/@href").extract()
for url in urls:
if url.find("xunlei") > 0:
r = Request(url, callback=self.parse_GetDownload_URL)
req.append(r)
return req
def parse_GetDownload_URL(self, response):
reload(sys)
sys.setdefaultencoding('utf-8')
hxs = HtmlXPathSelector(response)
#得到URL
urls =
hxs.select("//ul//li//a[@class='file_name']/@href").extract()
for url in urls:
self.f.write(url+"\n")
不过需要说明的是,不能一口气爬太多动画,因为太多的话,迅雷娘会派出座下首席守护娘————验证码姬!!

嘛,验证码这个不好突破,所以为了一定程度上缓和这个问题,一般爬的时候都要慢~~~一~~~点~~~,俗话说得好,不设时间间隔的爬虫都是耍流氓!!
另外,可以在start_urls里面设多个起始爬虫位置,也就是ZERO动漫中每部动画所在的页面,就可以一口气爬多部动画了~如上面代码所示!
另外一点,据测试,事实上最后爬到的那个最后的URL请求命令是一直在变的,所以不能说爬下来之后可以隔几天发给别人用,因为过几分钟那个链接就会失效了!只能说,爬完URL请尽快食用~
不用Crrapy
好吧,我本来就是计划上面那种方法写完就算了事了~但是突然想起,最近博文越写越短越写越短。。。于是,我决定把它水长长长长长长长长一点!!!方法就是,再写三种。。。
其实是因为考虑到,Scrapy这个东西写起来代码来虽然好用,但是配置起来是在太麻烦了,所以我也就自己笔记本电脑和实验室电脑搭了这个环境,家里台式都没弄,所以我就准备写个不用Scrapy环境的!!
其实也是超级简单的,因为Python里面有urlopen这个函数,可以获取网页源码,但是在不生成XPath节点的情况下,那就直接正则表达式把URL给抓出来咯。。【其实我是正则表达式苦手,学了这么久一直用不熟练,所以一般原则是——能不用,就不用。。】
要抓迅雷下载页面的URL就用<a \s*href=['\"](.+?xunlei.+?)['\"].*?>,而下载请求URL的话就是:href=['\"](http.+?sendfile.+?)['\"].*?>
同样的,和上面一样,爬的时候只要设置一下时间间隔,就可以完整的爬下全部下载链接;
由于Zero动漫中页面地址都是形如http://dmxz.zerodm.net/xiazai/XXXX.html的,XXXX是一个序号,这里为了代码简洁,爬多部动画的时候只要在map(GetXuneliURL,[2000,2029]) 后面的数组里面填入这个序号就可以了~【发现《中二病》第二季的序号是2000整诶。。好吧,其实我不怎么喜欢第二季。。】
import urllib2
import re
import time
def GetUrl(content,regexp):
return re.findall(regexp, content)
#获取下载链接
def GetDownLoadURL(pageurl):
content = urllib2.urlopen(pageurl).read()
regexp = r"href=['\"](http.+?sendfile.+?)['\"].*?>"
for url in GetUrl(content,regexp):
print url+"\n\n"
#获取下载链接所在页面URL
def GetXuneliURL(idx):
url = "http://dmxz.zerodm.net/xiazai/"+str(idx)+".html"
content = urllib2.urlopen(url).read()
regexp = r"<a\s*href=['\"](.+?xunlei.+?)['\"].*?>"
for download_page in GetUrl(content,regexp):
GetDownLoadURL(download_page)
time.sleep(1)
map(GetXuneliURL,[2000,2029])
Mathematica法
以前在这篇博文中研究过用Mathematica来爬虫,所以就顺手实现了一下Mma版本~
和之前那篇博文的区别就是,这里是直接用正则表达式来抓想要的东西的,而不是像以前那样傻乎乎的用Mma的匹配功能来自己模拟XPath。。。【以前为什么这么傻!!】
由于Mma一般爬的速度就非常慢,所以发现不设时间间隔一点问题都没有。。【这尼玛是啥优点。。
GetURL[xunleirul_] := Block[{content},
content = URLFetch[xunleirul];
Print /@ StringCases[content,
RegularExpression["href=['\"](http.+?sendfile.+?)['\"].*?>"]->"$1"]]
GetXuneliURL[idx_] := Block[{content, xunleipage},
content = URLFetch["http://dmxz.zerodm.net/xiazai/" ~~ ToString@idx ~~ ".html"];
xunleipage = StringCases[content,
RegularExpression["<a \s*href=['\"](.+?xunlei.+?)['\"].*?>"]->"$1"];
GetURL /@ xunleipage
]
GetXuneliURL[2000]
结果如下:

PHP版本
最后这个本来本着:一,造福社会,二,练习php的目的来做的,但是最后感觉不好使,就不真正放出来献丑了,而且代码极短,所以根本什么都没练习到嘛!!摔【所以两个目的都打水漂了
做一个php页面,然后方便自己以后在没有Python或者Mathematica的情况下,打开自己网站的某个页面,输入想要获取的下载链接的页面地址,然后就可以把结果转完了~
最后结果如下面所示:

其实我一开始是想用Js做的,毕竟最先想到的是怎么样输入,按钮交互这些,但是后来发现JS获取网页源码不怎么好搞,毕竟是客户端语言,而不是PHP这种服务端语言,所以就放弃了改用PHP,妈蛋为什么PHP按钮交互一定要用表单啊!!
之后遇到的第二个问题就是,我原本是在我的另一个主机上测试的,而不是本博客所在主机,那部主机当它爬到下载界面的地址的时候,比如说这个:http://kuai.xunlei.com/d/XVYmAQKzKgDgOtpS606?p=56866,再用file_get_contents去获取网页源码的时候,发现拿到的是迅雷看看的首页的源码,不管怎么测试都是这样,感觉就是在调用file_get_contents的时候被重定向了一样,弄了半天未果,然后把代码放到现在这部主机的时候发现就一点问题都没有了。。。さっぱり分からない。。。
第三个问题就是发现这个php方法爬没几部动画就很容易遭遇野生的验证码姬了,而且用这个方法的话,迅雷娘检测到的都是我这部主机的ip,所以如果给大家用的话,就会遭遇大量的验证码姬了。。。研究了一下,如果不用file_get_contents而改用Curl的话,好像可以做各种伪装,但是这个好像需要给php装点什么东西,或者配置点什么东西,主机没权限,所以。。。唉。。。难道VPS才是唯一的出路么??
最后,这个方法最不能忍受的一点就是,爬取的速度实在太。。。。。慢。。。。。了。。。
算了,代码先放着,以后PHP学成了再回来研究研究。。。
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en" lang="en">
<head>
<title>Zero动漫URL获取</title>
<link rel="stylesheet" type="text/css" href="common.css" />
</head>
<body>
<h1>根据zero动漫网站,查询迅雷下载地址</h1>
<?php
displayForm();
if ( isset( $_POST["submitted"] ) ) {
processForm();
}
function displayForm() {
?>
<h2>输入目录页面,形如http://dmxz.zerodm.net/xiazai/XXXX.html:</h2>
<form action="" method="post" style="width: 30em;">
<div>
<input type="hidden" name="submitted" value="1" />
<label for="url">URL:</label>
<input type="text" name="url" id="url" value="" />
<label> </label>
<input type="submit" name="submitButton" value="查询" />
</div>
</form>
<?php
}
function processForm() {
$url = $_POST["url"];
if ( !preg_match( '|^http(s)?\://|', $url ) ) $url = "http://$url";
$html = file_get_contents( $url );
preg_match_all( "/<a\s*href=['\"](.+?xunlei.+?)['\"].*?>/i",
$html, $matches );
echo '<div style="clear: both;"> </div>';
echo "<h2>查找" . htmlspecialchars( $url ) . "的目标链接如下:</h2>";
echo "<ul style='word-break: break-word;'>";
for ( $i = 0; $i < count( $matches[1] ); $i++ ) {
$xunleiurl = file_get_contents($matches[1][$i]);
preg_match_all( "/href=['\"](http.+?sendfile.+?)['\"].*?>/i",
$xunleiurl , $urlmatches );
for ( $k = 0; $k < count( $urlmatches[1] ); $k++ ) {
echo "<li>" . htmlspecialchars( $urlmatches[1][$k] ) . "</li>";
}
}
echo "</ul>";
}
?>
</body>
</html>
哟西~经过我这么一水,这文章长度马上就出来了。。质量嘛。。算了。。。
【完】
本文内容遵从CC版权协议,转载请注明出自http://www.kylen314.com

有点意思哈。。
哇塞,你的牢骚的那个板块实在怎么弄的呀,能提示个关键词不
就是css啊啊
又是技术文章,赞一个
节日快乐哟~
同嗨皮!
双节快乐哈~
技术流
话说,我貌似某次下灼眼的夏娜某个片子,最后也是从zero下的。所以这个地方有很多冷僻的资源?
我硬盘500+G的动画基本都来自这里。。。
PO主有才,我最近也在学 Python,嘿嘿,喜欢验证码姬(ps:我是迅雷派来的卧底)__________________
迅雷卧底?你在那工作?看到你的头像没啥印象,看到最后的下横线就突然想起来,啊,这个人以前在我博客留过言。。
原来特殊的下划线还有这功能 ,我头像不固定的,但还是同一个系列________________我还没毕业,不过工作的话,目前是签的他_________________________
,我头像不固定的,但还是同一个系列________________我还没毕业,不过工作的话,目前是签的他_________________________
哦?迅雷是在深圳么?请到时务必不要举报我!!2333333
正考虑拿同样的题目练手呢,我也是用 zero 迅雷快传下动漫的 __________________________
__________________________
这道题没啥好练手的。。你看代码这么短就知道了。。就是一个抓-匹配-抓-匹配的过程。。想练手可以去python challenge那里玩~
蒽蒽,原理懂的,是想多点 Python 的编码经验,因为 Windows 和 Linux 环境都撞了一下,一些日常处理的脚本就用 Python 写了,就不用写个 batch 版本再写个 bash 版本了。The Python Challenge Marked________________
写个旋风吧/w
看了一下,要改的话代码基本没差。。。只是个人从不用旋风那个东西。。。而且那个URL拷到迅雷里也用不了。。只能用QQ自己的。。
几乎都用旋风。。
多年迅雷白金会员路过。。好像很多年前因为什么原因我很排斥腾讯的下载器。。
现在挺不错的啊/w 为什么呢。
好像以前的用户体验不是很好,不过根据疼讯一直以来的作风,现在应该很不错了。。你是这几年来我第一次听说有在用旋风的人。。。迅雷的势力太大了233
旋风 还是挺不错的/w/w 我见到好多人用的说。。。
世界不同。。。刚刚问了一下实验室有多少人知道,他们都说“听过”。。
说不是软文,还要删掉。这不就提醒别人这是软文么?
主要是不这样介绍的话,后面那些东西感觉说不清楚。。。而且写完后一读才发现像软文。。。
soga
關於開頭說的下載很麻煩,我表示絕對同意,非常同意,特別是極影…….不想吐槽了。其實最大的收穫是…….zero網站…我得趕緊去補充資源,我已經飢渴難耐了
我现在一般使用这个脚本(https://github.com/Vespa314/zerodm-download/tree/master/Zerodm_PY),各种爽
剛剛去github上發現介紹說明那裡的圖片掛了
应该是github自己转图源的问题。。好久没动那个了,之前还好好的;以前也出现过类似的问题,过一阵子就好了。。囧囧
[电视机] 不错,过来支持一下