Crossword Puzzle Maker
 之前找OS X游戏的时候在一个忘记了什么网站上看到了“Black ink”的Crossword Puzzle游戏,中文就是纵横字谜啦,不过好贵,而且我周围基本没见过有人玩过(感觉上一次见人玩大概就是无数年前Big Bang第一季第一集的时候了。。),自己更加没有刚需,所以就没理了;
之前找OS X游戏的时候在一个忘记了什么网站上看到了“Black ink”的Crossword Puzzle游戏,中文就是纵横字谜啦,不过好贵,而且我周围基本没见过有人玩过(感觉上一次见人玩大概就是无数年前Big Bang第一季第一集的时候了。。),自己更加没有刚需,所以就没理了;
然后某天晚上躺在床上脑洞的时候突然想到。。。啊咧,Mathematica的DictionaryLookup函数不是有全部的英语单词么?WordData不是可以获得单词的各种信息,包括Definition么?那我是不是可以利用这个生成单词列表,然后设计一个算法自动构造出一个Crossword Puzzle的谜题来?然后以前玩绘制Pokemon图鉴的时候玩过Grid这个屌炸天的函数,还可以用Dynamic来做一些联动的动态操作,so,本文就是这个脑洞的实现。。
生成单词列表
其实我自己从来没玩过Crossword Puzzle。。(所以我为什么会想到做这种东西),凭直觉大概觉得单词不会太长,也不会太短。。。。吧。。。。
于是,先找出所有单词里面长度4~7的单词:
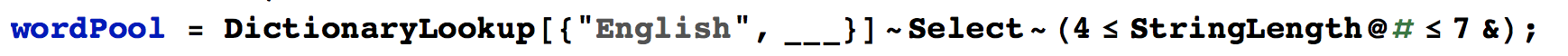
Mathematica Code
随便看了一下,发现其实有一大部分比例单词第一个字母是大写,而且不是常用词,计划把他们过滤掉,另外,用WordData的时候也发现不是所有词都可以获取到Definition的,这些词也要扔掉!
首先,WordData第一次运行需要从W|A上面下载一些云上的数据,所以可以随便搞个单词来先把数据抓回来:
![]()
Mathematica Code
上面这个运行一下,等它下载完就可以了。
而且返回来的数据我们要获取其中Definition那部分,所以需要准备一个函数来获取定义:
![]()
Mathematica Code
然后过滤掉首字母大写和没定义的:

Mathematica Code
接下来随机找出我们指定数目的单词即可:

Mathematica Code
wordlist即所谓求。
构造谜题
构造谜题这个算法其实不难想,随便脑补一下大概就可以想到了,但是我发现这个算法Mathematica实现起来实在是。。。太尼玛艰难了,当然,我模仿别的语言,用各种For,Table,If函数确实可以翻译出来,但是既然不美,就索性不要去创造!【后来我想了想,可能是我mma在使用模式匹配上面的功力不够】
so,我用python实现了一下,思路很简单,就是随便挑一个单词放棋盘上,然后再不断地找下一个单词,在合适的位置放上去,递归求解就是了;
这个算法用python实现起来很快,我写的第一个可以输出结果的代码,加上空行注释,100行都不到,后面增加了一些结果打印函数,迭代中每次随机找单词和随机找位置,把结果导出到文本以便后期Mathematica调用,代码也是150行都不到。。
但是吐个槽,虽然python实现这种东西代码量远远小于C++,但是再给我一次机会,再也不敢用python了,对于这种需要迭代求解,每次往递归函数里面传进各种标记信息变量的时候,python这种不允许指定是值传递还是引用传递的语法,你就只能用a[:]来值传递一维的list,用copy.deepcopy来值传递二维list,难受死了,不是写得难受,而是感觉代码失去了某种美感。。
代码如下:
import copy,sys,random
# 单词列表
wordstring = "buckles,killed,rubato,collect,......."
WORDPOOL = wordstring.split(',')
random.shuffle(WORDPOOL)
BOARD_SIZE = 33
class CRecord:
def __init__(self, m_size,m_wordpool):
self.indexTable = [set() for x in range(26)]
self.board = [['-' for x in range(m_size)] for x in range(m_size)]
self.dirFlag = [[0 for x in range(m_size)] for x in range(m_size)]
self.wordpool = m_wordpool
self.items = []
# 显示结果
def ShowResult(record):
output = ""
for i in record.board:
for j in i:
output += j
output += "\n"
print output
# 设置单词
def SetBoard(record, word, i, j, IsRow):
record_copy = copy.deepcopy(record)
for (idx,ch) in enumerate(word):
ci = i + (not IsRow)*idx
cj = j + IsRow*idx
record_copy.dirFlag[ci][cj] |= (0x01 if IsRow else 0x02)
record_copy.board[ci][cj] = ch
record_copy.indexTable[ord(ch)-ord('a')].add((ci,cj))
record_copy.items.append([word,i,j,IsRow])
# 如果结束
if 0 == len(record_copy.wordpool):
ShowResult(record)
sys.exit(0)
return record_copy
# 检查在指定位置指定方向放单词是否合法
def ValidCheck(record, word, i, j, IsRow):
L = len(word)
if i < 0 or j < 0:
return False
# 横/纵向溢出检测
if IsRow and j + L - 1 >= BOARD_SIZE:
return False
if not IsRow and i + L - 1 >= BOARD_SIZE:
return False
# 单词左边/上边不可以已经有字母
if IsRow and j-1 >= 0 and record.board[i][j-1] != '-':
return False
if not IsRow and i-1 >= 0 and record.board[i-1][j] != '-':
return False
# 单词尾部下一位置不可以有单词
if IsRow and j+L < BOARD_SIZE and record.board[i][j+L] != '-':
return False
if not IsRow and i+L < BOARD_SIZE and record.board[i+L][j] != '-':
return False
for (idx,ch) in enumerate(word):
ci = i + (not IsRow)*idx
cj = j + IsRow*idx
# 如果和已有单词不匹配
if record.board[ci][cj] != '-' and record.board[ci][cj] != ch:
return False
if record.board[ci][cj] == '-':#如果位置为空
# 横向单词上下不可以有纵向单词的尾部/头部
if IsRow and ci-1 >= 0 and record.board[ci-1][cj] != '-' and record.dirFlag[ci-1][cj] & 0x02:
return False
if IsRow and ci+1 < BOARD_SIZE and record.board[ci+1][cj] != '-' and record.dirFlag[ci+1][cj] & 0x02:
return False
# 纵向单词左右不可以有横向单词的尾部/头部
if not IsRow and cj-1 >= 0 and record.board[ci][cj-1] != '-' and record.dirFlag[ci][cj-1] & 0x01:
return False
if not IsRow and cj+1 < BOARD_SIZE and record.board[ci][cj+1] != '-' and record.dirFlag[ci][cj+1] & 0x01:
return False
return True
# 迭代计算
def Calculate(record, curWord, i, j, isrow):
if ValidCheck(record, curWord, i, j, isrow):
record_t = SetBoard(record, curWord, i, j, isrow)
for word in record.wordpool:
Iter(copy.deepcopy(record_t), word)
# 随机排序yield返回
def RandomSort(l):
random.shuffle(l)
for i in l:
yield i
def Iter(record, curWord):
global WORDPOOL
global BOARD_SIZE
record.wordpool.remove(curWord)
# 如果是第一个单词,放在棋盘中间
if len(record.wordpool) == len(WORDPOOL)-1:
for isrow in RandomSort([True,False]):
Calculate(record, curWord, (BOARD_SIZE-len(curWord)*(not isrow))//2, (BOARD_SIZE-len(curWord)*isrow)//2, isrow)
else:# 否则,随机挑个字母,随机挑个位置
for (idx, ch) in enumerate(curWord):
for pos in RandomSort(list(record.indexTable[ord(ch)-ord('a')])):
for isrow in RandomSort([True,False]):
Calculate(record, curWord, pos[0]-idx*(not isrow), pos[1]-idx*isrow, isrow)
if __name__ == "__main__":
record = CRecord(BOARD_SIZE, WORDPOOL)
for word in record.wordpool:
Iter(copy.deepcopy(record), word)
本文中代码删减了几个无谓的函数,完整版请看Github
由于不少地方用了random.shuffle函数,所以每次跑出来的结果都是不一样的,结果大概如下(左图是调试的时候一个参考):
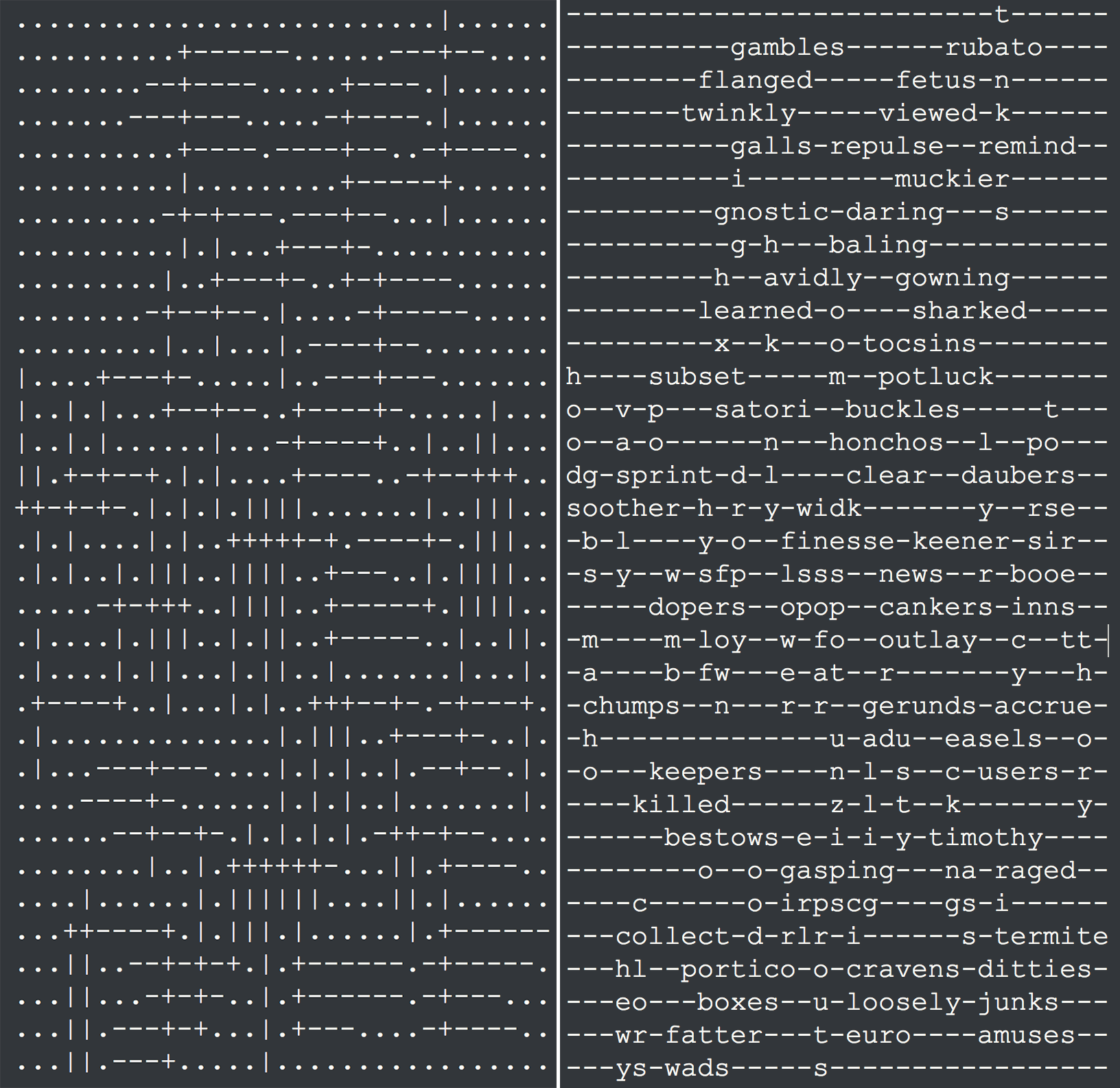
然后导出到Mathematica的文本格式大概如下:
finesse 17 14 - encored 17 20 | outlay 20 20 - wisp 16 15 | cankers 19 20 - bocks 13 18 | insofar 16 16 | gerunds 22 19 - flower 17 14 | galling 22 19 | clear 15 18 - honchos 14 17 - decking 22 24 | . . .
标记好单词,起点坐标,横竖信息。
显示谜题
首先,读进来数据,然后计算出有效棋盘大小,再然后初始化一个grid变量,全部为空字符串:

Mathematica Code
然后对grid变量,在正确的位置赋值上谜题答案的字母(要分横纵两种情况赋值):

Mathematica Code
在画棋盘之前需要准备两个小函数,一个是设置格子背景颜色的,一个是线框:

Mathematica Code
好了,可以试着把棋盘画出来了,一行:

Mathematica Code
结果如下:

感觉还行。。
但是。。。这个是答案啊!!不是谜题啊摔!!!你搞错了吧。。。
好好好,画谜题就画谜题。。
和画答案的区别在于,不要把字母标上,而是在起始位置标上数字,而联动操作的时候,设置一个按钮面板,点击不同的数,首先会在界面上高亮相应的行或列(or行和列),并且会在面板下面显示行列单词的谜题(就是词典里面这个单词的全部定义啦~)
代码如下:

Mathematica Code
录了个gif:

这种方法有两个缺陷,第一,要做出自动判断输入结果是对是错这个效果很麻烦(不是不可以),因为Table内每个元素绑定Dynamic的时候会有点限制。。另外一个问题就是自己输入结果的时候第一个字母处那个数字index要手动删掉。。
所有代码放在Github,有爱自取。
本来想做一个cdf演示直接挂博客的,但是,你看我这文章版面宽度,也懒了。。
总结
总之,食用方法就是先Mathematica生成单词列表,然后把列表拷到python代码中,运行一下,表格将会导出到一个文件中,再用Mathematica读取这个文件,构造界面。。
年前最后一篇博文,赶毕设屁屁踢去了。。民那桑,哈皮牛耶~

【完】
本文内容遵从CC版权协议,转载请注明出自http://www.kylen314.com

赞脑洞!
我看完只想说一句 你TM脑洞也太大了……好赞!
偶然经过贵站,盼望回访,xrpmoon
哈皮牛耶~这种纵横字谜太枯燥了不想玩…不过我对word->definition这个很感兴趣,打算有空把牛津词典的内容弄出来….
我。。也不喜欢玩这个游戏。。
突然想到一个问题,已知这个游戏的谜面布局,如何在词典中找出单词实现这个谜面。。
假定谜底的内容是我们掌握字典的子集.若是我..1. 若它的definition和我们掌握的definition基本一样,那非常好办字典的definition建立倒排索引, 比如我写的这个, http://argcv.com/articles/3008.c谜面作为query直接查询就搞定.若完全一样,连分词都不用,直接definition->word的map一建立就行.2. 若两边的definition不太一样…那么就有点复杂首先按照长度寻找每个位置的candidates,然后查看限制条件,以尾部谜面举例.确定依赖关系后,发现3依赖10,纵向3(长度10)的单词,第四个字母是横向10(长度5)的首字母那么列举所有10的首字母保存为一个set.去除3这个中第四个字母不是那个set中的字典.然后字典的definition建立倒排索引, 拿谜面去查这个索引.过滤掉一些candidates,并将其按照查询结果排序.最后,再确定依赖.比如3依赖10,那先给10选定一个结果,再在3的里面根据10的约束再选一个结果,若3中没有结果,那么10换成第二个结果(总之就是回溯法,很容易的)..就这样,你哪怕对谜面中的definition稍作修改我都可以很容易找到解
嗯..我想了下,第二种就是多了个预处理
但是我总觉得这个好慢的样子。。
哪方面慢?倒排索引速度很快的,然后可以存在leveldb之类里面,可以被反复使用.若definition是全内容完全一致的话,持久化一个map非常轻松,然后反过来查一下即可.根据definition找到的key数量大多是非常少的.,然后建立一个依赖树,逐个填入即可,连预处理都不用.速度接近O(n)一大坨过滤,解释之类的,还是考虑着若definition有很多而你实际谜面中只取某一段这种事情.那样的话一般分词+倒排索引查询速度也很快(各种搜索引擎都是这样的原理),虽然有好多结果,但真正的结果一般前两个就是.
等一下,我觉得我们讨论的是同一个东西么?我想说的是,假设我们有一个上面第一幅黑白格局面但是没有单词的棋局,然后从词典中构造出可以放入这个谜题的“答案”来。
额….我错了…我理解成解答了….不过我之前的内容就是尝试构造一组内容可以fit它,(大约就是这个原因你才又继续又讨论了一句……..)简单说就是编译格局得到一个依赖森林.然后从叶子开始往里面丢单词,回溯法搞定就可以.(可能有超过一个解,我之前描述了好多过程尝试把这些解和某个谜面匹配….)我想了下,多重依赖比较好解决,循环依赖的处理细节好像要想一下….总之我差不多就是想到这么个暴破方案,因为依赖看起来也不算复杂.我这两天若有空我来撸个代码实现下.输入:1. 格局(一组点,参数有坐标,长度,横纵)2. 可选单词列表输出:每个点的单词
加油!!我就是感觉暴搜有点伤。。之前写这篇的时候去google搜了一下图片,发现有很多精致的对称的谜面,故有此一问;
Hi, 博主好,请问你的Mma代码格式化是咋操作的,看着非常不错。我简单试用了下L.Shifrin的格式化插件,虽然凑合有些效果,但是感觉不理想。这个帖子,是我玩格式化代码的目前的进展。http://hypergroups.cn/Mathematica%E4%BB%A3%E7%A0%81%E6%A0%BC%E5%BC%8F%E5%8C%96%E6%B5%8B%E8%AF%95/
改自google-code-prettify的lang-mma.js和prettify-mma.css,具体可以参考withparadox2大大的博客
噢,这个代码高亮的我前天刚用上,那比如你这篇的MathematicaCode里,有的看起来有对齐的效果,是有像SE里手动编辑不,就是比如@号的左右空格,新行前的空格对齐,括号匹配等,这方面是否有搞过。SE@http://mathematica.stackexchange.com/questions/2809/programmatic-formatting-for-mathematica-code-possible
这些细节的我没注意过诶,我也没调整过。。都是mma中直接复制出来贴博客里的。。
哦哦,好的,看来在笔记前端格式化[包括部分手工]然后再复制/转换出来是一种方法。对我的操作上还是有启发,之前我过于偏重生成单元表达式再格式化,可以先格式化单元再生成单元表达式。
真厉害,网页可以改成响应式的,这样在宽屏电脑显示的文章宽度就比较大了
好多人提过这事了。。我15年初就在年度计划里加上过修改博客主题这事了。。然而现在还在2016年的年度计划里。。。拖延症伤不起。。
呀,果然这是15年初的博文。。TAT