随机数重复长度の研究
前言:过了那么久。。。我终于发现。。。我的数学真的快不行了。。。
好吧,事情是这样子的,突然一个基友(@白菜)问了我一个问题,他用matlab产生了一组随机数,规模很大,但是程序按照他的预期,应该是不希望出现重复的随机数,然后问我大概一般多长会出现重复。
然后我一看,额,这尼玛不是一道概率题么。。
然后就算了一下:
虽然那个基友程序跑的是0~1之间的随机数,但是不要紧,我们可以用整数来模拟:假设随机数的生成是1~N之间的一个均匀分布;
那么第一个数就出现重复的概率是:0
第二个数就出现重复的概率是:\(\dfrac{1}{N}\)
第三个数才出现重复的概率是:\(\dfrac{N-1}{N}\times\dfrac{2}{N}\)
第四个的话就是:\(\dfrac{N-1}{N}\times\dfrac{N-2}{N}\times\dfrac{3}{N}\)
第k个数就出现重复的概率自然就是:\(\dfrac{N-1}{N}\times\dfrac{N-2}{N}\times…\times\dfrac{N-k+2}{N}\times\dfrac{k-1}{N}\)
其中k最大只能取到N+1,然后把上面最后的表达式化简一下就是: 【我为什么说我数学变差了,因为我算上面的公式算错了好多遍。。】
【我为什么说我数学变差了,因为我算上面的公式算错了好多遍。。】
假设我们N=30,那么出现重复的长度就是上面那个概率f1(N,k)乘以k求个和而已:
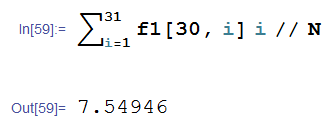 也就是说,假设随机数范围的范围1~30的话,那么预计8个左右就会出现重复【数学期望意义上】。
也就是说,假设随机数范围的范围1~30的话,那么预计8个左右就会出现重复【数学期望意义上】。
那么这个期望值随着N是怎么变化的呢?为了算出这个,我们首先需要对上面的公式进行“编程意义上”的变形,为啥呢?你可以想象,每次计算一个上面定义的f1所需要的计算量,这是很恐怖的东西,我算了一下,N一提高到5000,基本就跪了。
简单的,我们希望可以通过f1(N,k-1)算出f1(N,k)出来,这两个的关系如下:
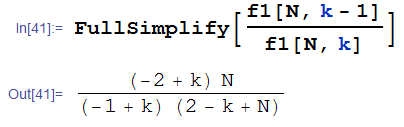
【我为什么说我数学变差的证据二就是上面那个我手算了三遍才算对。。。】
所以我们可以写出一个新的递推公式来求上面的f1:
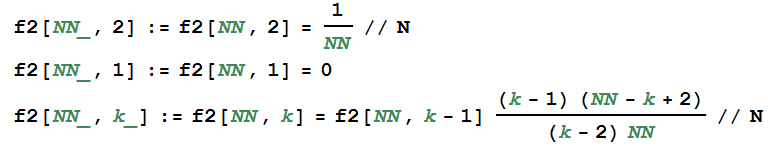 我们来对比一下运行速度:
我们来对比一下运行速度:
 这已经不是被爆了几条街的问题了吧。。。
这已经不是被爆了几条街的问题了吧。。。
然后我们就可以画一下那条曲线: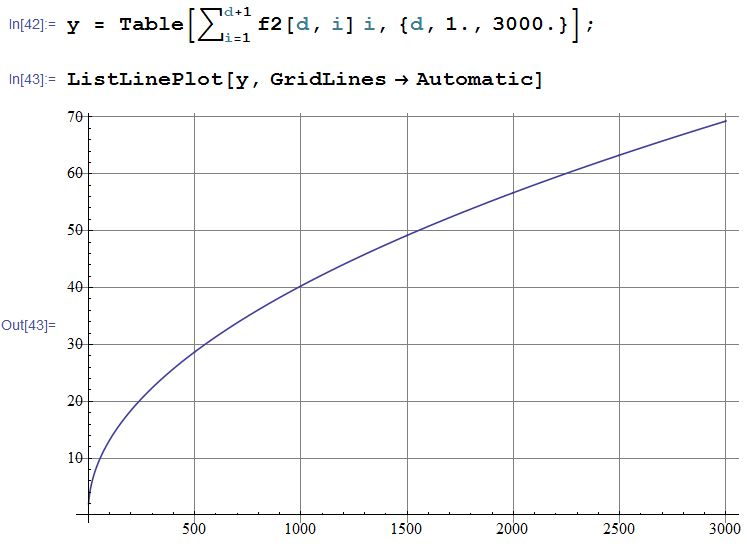 这个曲线很像什么?显然的,0.5次方的曲线!!我们可以拟合一下看一下结果:
这个曲线很像什么?显然的,0.5次方的曲线!!我们可以拟合一下看一下结果:
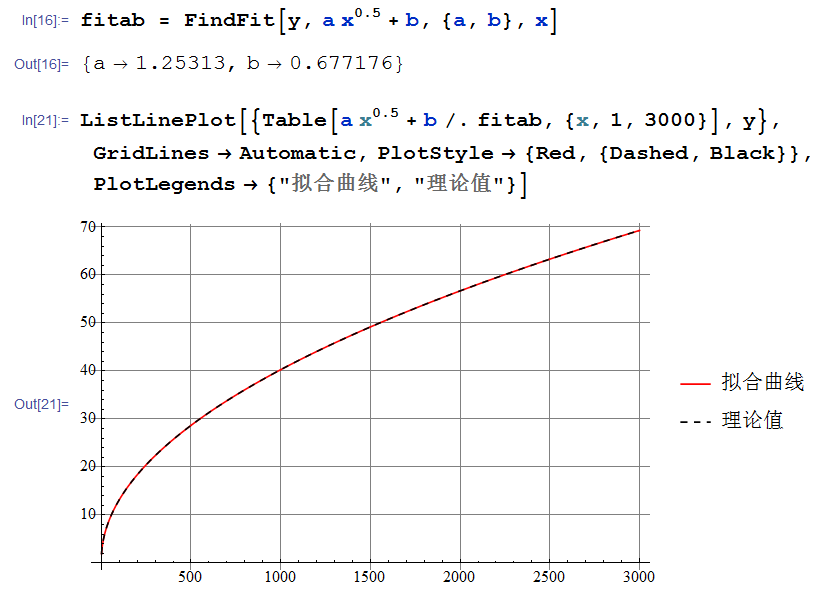 我算了一下,误差绝对可以忽略不计!即便当N取到65535,上面算过,期望重复长度是321.513,而这个拟合的算出来是321.475,所以这个可以很好的用来做这方面的分析!!
我算了一下,误差绝对可以忽略不计!即便当N取到65535,上面算过,期望重复长度是321.513,而这个拟合的算出来是321.475,所以这个可以很好的用来做这方面的分析!!
就算换成随机数范围是0~1,我们假设里面每个浮点数用8字节来表示,那么总范围也就是等价于整数里面的N=2^64,但是算出来的期望重复长度是: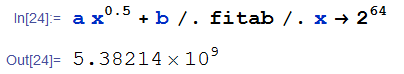
所以,少年,你自己的程序看着办吧。。。
其实可能有人想起来了,这个问题本质上和我们以前高中很喜欢出的某道概率题很像:一个班50人,那么有两个人生日是同一天的概率是多少?
其实这个概率是就是我们上面的函数里面,N取365,k取1~50的累加: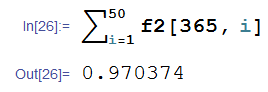
生日的这个重复生日的概率随着班级人数规模增加的曲线是: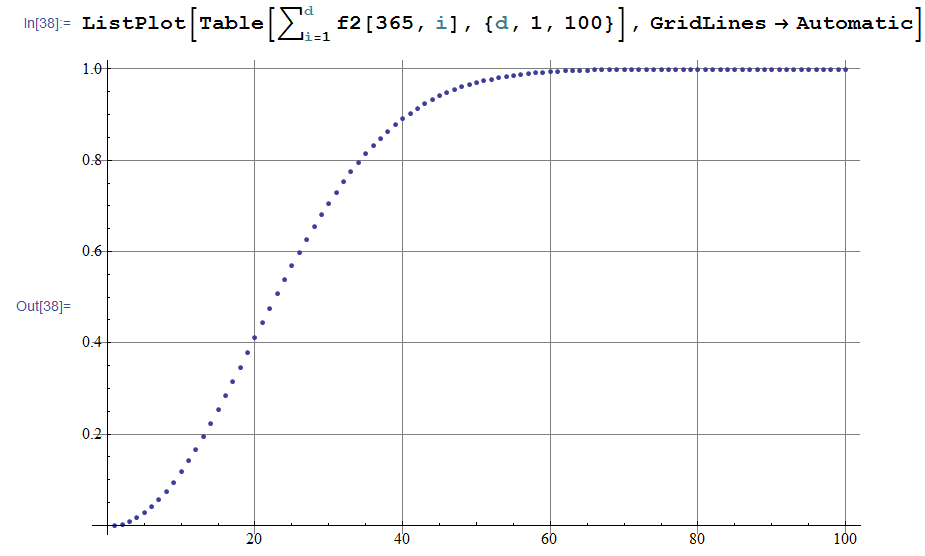 对于N=365,期望的重复人数的24.6166,这里我们可以看到,当随机数的长度达到重复长度的期望值的时候,就基本有一半的可能性会发生随机数重复了,当再多一倍时,那基本就是妥妥的已经发生了随机数重复了!!
对于N=365,期望的重复人数的24.6166,这里我们可以看到,当随机数的长度达到重复长度的期望值的时候,就基本有一半的可能性会发生随机数重复了,当再多一倍时,那基本就是妥妥的已经发生了随机数重复了!!
【完】
本文内容遵从CC版权协议,转载请注明出自http://www.kylen314.com

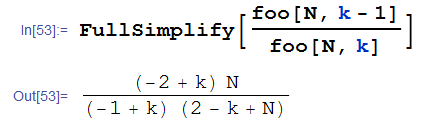{kind=link}
推算一下就知道是一个伪高斯啊…Pr(k)~2*k*exp(-k^2/n)期望值g=sqrt(n/pi)/2