Mathematica破解字母频率密码
好吧。。。我承认最近玩mathematica玩的有点疯。。。《あまちゃん》的影评躺在博客草稿里面躺了快一个月了。。。算了,不管了!
以前玩一个叫做World of Abstractica的字谜游戏的时候,就经常用mathematica来解决里面的一些比较坑爹的问题,反正这个游戏的规则都说了,你可以利用一切你手边的工具,包括任意软件和网络,搜索引擎等东西 …所以不能怪我。。。
好吧,扯远了,其实由于里面涉及的字谜比较多,所以mathematica的话,用的最多的还是里面的 DictionaryLookup函数,它可以返回各门语言的单词,还可以根据正则表达式之类的输入来搜索单词, 比如说下面这个WOA的例子之类的。。。
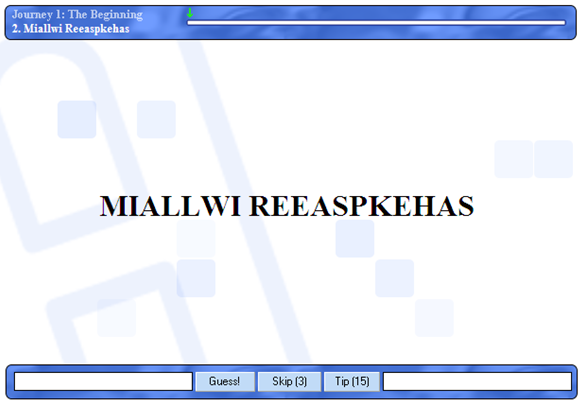
要找出由上面字母组成的单词,那么写mathematica就是一行代码的事情。。。
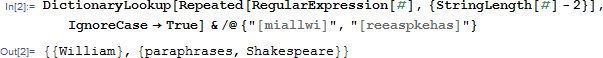
然后前一阵子有一天没事干,就想研究一下英文字母里面每个字母出现的频率,用的还是上面的DictionaryLookup函数来获取所有单词的信息,代码和结果如下。。。 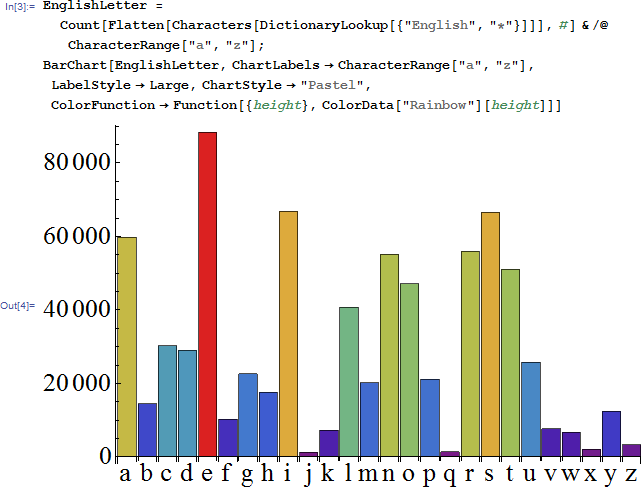
把上面的结果以列表的形式显示出来,对每个字母出现的频率排了个序。。。
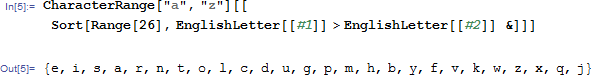
不出所料的是,第一名必然是元音,另外,发现元音前五才占了三个,有人提醒我,这个词典里面每个字母出现的频率不一定代表着海量文章中每个字母出现的频率。。。
显然的,字典里面每个单词出现的频率显然不是一样的,而且不同时代不同的单词的频率也是不一样的。。。而且我们相对更感兴趣的显然在实际运用中每个字母的出现频率,而非词典中每个字母的频率,对于很多年前研究电脑键盘该怎么分布的人更是如此!
于是我就导入了mathematica里面自带的几本书,来做了一个统计,首先是字母的出现频率。。。。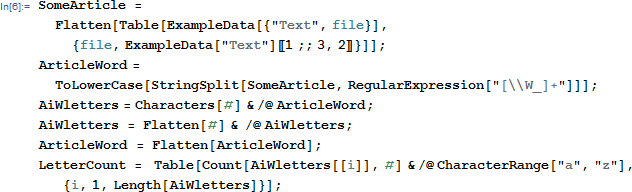
统计结果如下。。。
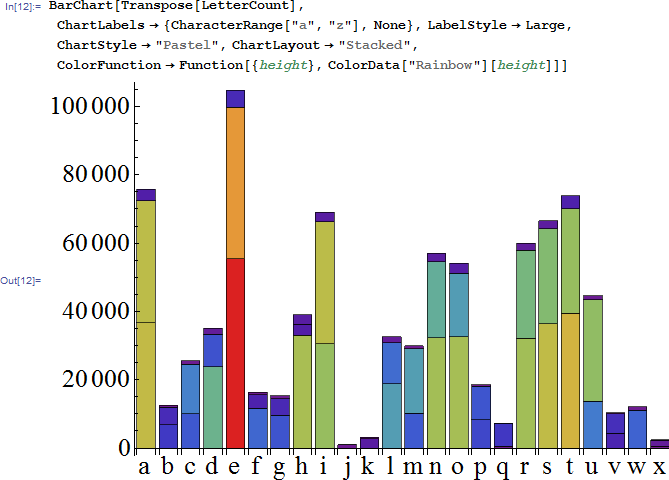
和词典的字母频率放在一起对比一下。。。确实有些差别。。。虽然字母E依旧是一柱擎天!!
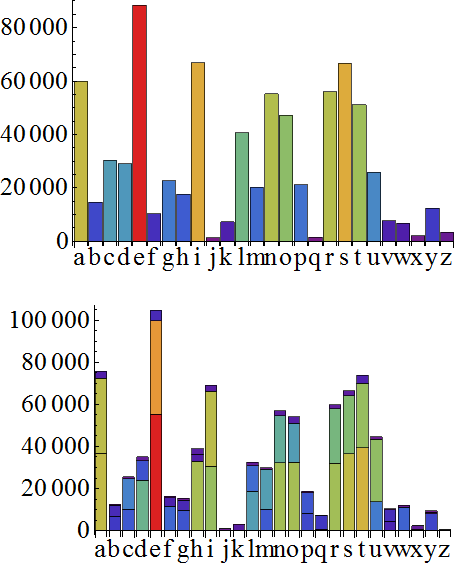
统计完字母后,由于突然感兴趣,所以统计一下不同单词的出现频率。。。由于单词数量种类太多,我们这里就只列举出TOP20!

【还是负责任地说一句吧,其实我偷懒了,分割单词的代码没有太用心,所以比如don’t这种单词,会划分成don和t,I’d会分解成I和d,所以才会导致字母d居然在单词榜上有名!!】
然后为了继续玩弄mathematica,我想到了一个主意!
如果是熟悉侦探小说福尔摩斯的应该会很熟悉,不熟悉的估计也听过一种密码————跳舞的小人【其实真名什么的我真的不知道,福尔摩斯里面用的章节名就是这个。。另外,其实爱伦坡和死神小学生,还有一些别的作品里面也都出现过这一类的密码。。只是已经没有什么新意了,也都是附带提一下的那种。。】

这种密码就是一种图案代表一个字母,你只要知道每个图案是什么字母,这个就可以直接破解了。。
人为破解这一列密码的话,步骤一般就是先找出最高频率的图像来,认为它是e,【我们上面也算过,不管词典还是写作中字母E都是”一柱擎天”!!】
然后再来推别的,比如跟据上面测试的结果,单词the出现的频率最高,而且是相当的高,那么找到出现频率最高的三个字母的组合,并且尾部是E,那么也很快可以定位出t和h来,再然后就是找一个字母的,一般不是a就是I,但是I经常出现在句首,所以也可以加以判断;再之后可以看一下现在的一些已经破解出来的单词,填空!!
总而言之,言而总之,反正就是加入我们对英语单词的先验知识,只要密码文足够长,那么破解是很有可能的。。。【实验室师弟就说他们以前的信息安全考试的一道题就是加密了英文版的 《水调歌头》,然后26个字母,一个一分。。。】
然后为了模拟这一种情况,我们首先随机设计一种映射关系,26 个字母的随机互换。。。比如下面这个规则。。。
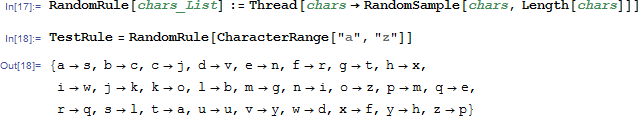
然后我们找一篇测试文章来加密,就用mathematica自带数据里面的 《傲慢与偏见》 的前100000个字符:
![]()
待加密文章的前1000个字符如下。。。

然后加密。。。。mathematica里面也是一行超级简单的函数:
![]()
加密后的密文的前1000个字符如下,好,我们已经认不得这篇文章了。。。【如果根据人脑判断的话,一瞬间就可以知道a被变成哪个字母了。。】

为了破解,我们需要再建立一个参考的数据,用来统计单词的分布的,还是这篇文章,后200000个字符。。。【其实当时我是想用爱丽丝梦游仙境的文章来的,后来发现mathematica里面这篇文章长度不及《傲慢与偏见》的十分之一,而且害怕不同作者”文风”不一样,用词频率差异比较大,导致破解失败,所以才选了同一篇。。。原谅我。。】

显示一个这个参考模板部分的前1000个字符。。【《傲慢与偏见》这篇文章在mathematica中总共600000多个字符,所以加密和参考两部分不会有重复的部分。。】

然后我们写一个字母统计频率的函数。。。
得到加密后的文章和参考模板的每个字母出现频率排序的序列: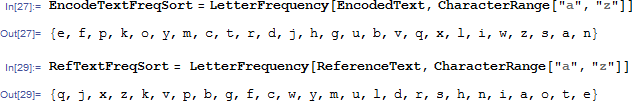
如果字母出现的频率靠谱的话,我们只要一一对应,就应该可以作为解码的映射了。。如果。。嗯。。这个前提很重要。。
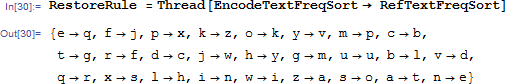
然后我们看看解密出来的文章的前1000个字符的情况。。。

好吧。。。失败了。。。喜闻乐见。。【都说大前提很重要的啦。。】
上帝视角,我们利用一开始的已知的加密规则【实际中破译前是不可能知道的】和我们算出来的解密规则联立起来,看看我们这个解密出来的结果实质上是一个什么过程。。。
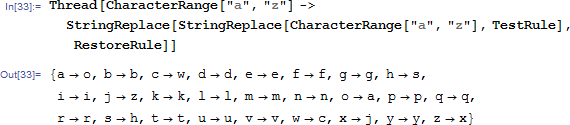
也就是说原来密文中的a被我们算成o,b算对了,c变成了w之类的。。。
但是一眼看上去,其实大部分解密还是对的,不是么?统计一下正确的有多少个。。。
![]()
好吧,还有9个字母算错了,2/3 少一点。。。
原因很容易查明白,比如我们把整本书分成n段,每段10000个字符,统计这每10000个字符里面每个字母出现的频率。。。结果如下。。。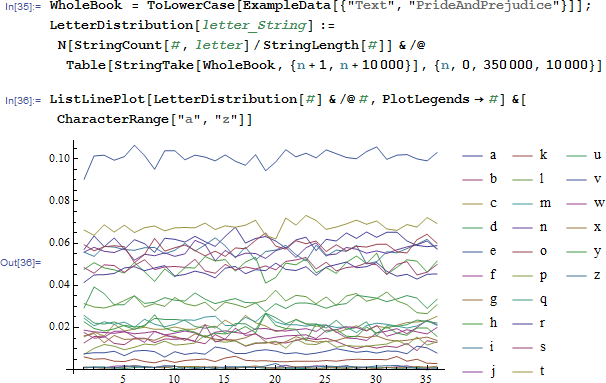
花花绿绿,颜色很乱不要在意,重点是,除了字母e有着绝对的压倒性的优势,一定可以被识别对外,其他的其实都很容易弄混,也就是我们上面那个算法对于出现频率很低的字母基本不具备破译特性。。
下面是我们上面参考模板文章的每个字母出现的频数。。。

这怎么办呢?想起了之前说的mathematica里面的字典没?【嗯,其实这是”伏笔”!!】嗯,没错,你解密的结果就算是错的,也要每个单词也要出现在词典里面啊;
所以,我的做法是,对于解密出来的不怎么正确的那篇文章里面的每个 “单词”,如果这个 “单词” 并没有出现在词典里面,那么我们就在词典里面找一个离这个 “单词” 最 “接近” 的一个真正合法的单词;如果有,就算是错的,我们也认为我们破译对了。
那么这个”最接近”的单词首先要具有的特性就是什么呢?————是和原来的单词等长!!【不用解释吧。。】所以,我们需要按照长度建立一张词典索引表。

验证一下,找出长度为3的前10个单词。。
![]()
嗯,没错!
然后就是定义 “最近” 这个概念了,有人提出一种思路,就是根据相应位置的字母在字母表里面的距离,但是用这个方法,虽然最后也确实”差不多”翻译出来了,但是我觉得还是很不对劲,毕竟你说字母e要被翻译成字母f,这个距离在字母表里面是1,但是基本不可能嘛。。。
而根据我们上面的计算,我们可以把字母出现的频率作为远近的依据,就像上面26条线一样,靠的越近,那么他们就越有可能被转换错误。。。比如i和t的频率很接近,那么如果有个破译出来的单词是iack,不是个单词,如果按照字母表的情况来说,那么离他最近的单词是jack,或者hack,但是根据我们之前算的结果,不管是j还是h,他们俩和i的出现频率都相差比较大,相反,我们会认为最近的单词是tack反而更加合理!!
所以按照上述说法,写了一个查找最近的单词的功能的函数:

验证一下,比如上面解码出来的错误的结果的第一个单词 “wsopter”,这显然不是单词,根据上面规则找一下离它最近的那个单词:
![]() 哈,正解!!
哈,正解!!
然后我们就是要提取出这个的变换规则来,像上面那个例子,我们需要把w变成c,s变成h,a变成o,写个函数实现一下: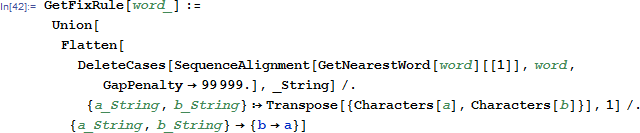 测试一下:
测试一下:
![]()
好了,工具已全,接下来就是试验了,但是————————首先,你需要分割出单词来。。。还是让正则表达式来干。。【额。。。还是那个偷懒的版本,算了,别在意。。】
![]()
显示一下前100个”单词”看看。。。
然后我们计算出每一个不是单词(就是没有出现在词典里)的”单词”要变换成离它最近的单词(词典里有的)所需要的变换,然后把这些变换累积统计一下,看一下结果。。。如下。。

然后我们找出这些变换里面频数超过最高频数的变换的频数的10 % 的变换 :【好绕。。】
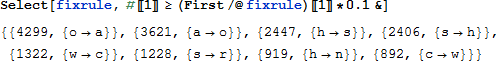
为了验证结果可靠性,先让我们先写一个函数统计一下翻译的结果的单词中不是合法单词(没有出现在词典里)的个数:
![]()
原来最开始的破译结果中不是单词的个数是。。。
![]()
其中原本的所有合法加非法的单词的数目是。。。。
![]()
也就是原本的翻译结果中大半都是错的,即便字母已经有17个是正确的了,但是显然很好理解,单词的错误率必然大于字母的错误率,因为单词是字母组成的,单词里面只要错一个字母,很有可能就不是单词了。。
然后把之前的解密规则修改一下,加上现在的新的结果,虽然我们上面提出频数超过10 % 的变换里面,有8个,但是我们只能用其中的6个,比如第三个 {2447, {h ->s}} 告诉我们需要把我们初步的破译的结果中的h变成s,但是倒数第二个 {919, {h ->n}} 又告诉我们要把h换成n,虽然它出现的频数也很高,但是我们也必须把它舍弃了。。。因为h已经”名花有主”了。。。
然后就得到新的转换规则了。。。统计一下新的规则下还有多少单词是错的。。。

已经10 % 不到了。。。
再来看看新的规则来解密的结果是什么样子的?

基本是完全翻译出来了!!
还是看看新的规则联立上上帝视角的加密规则,实质上做了一个什么变换
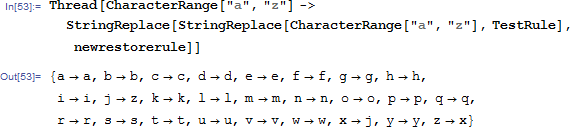
发现基本都是恢复了,但是还有几个变换是错误的。。。把它们找出来。。
![]()
就这三个了!!
然后这里我就卡了很久了。。。因为我真的找不到什么算法可以把这三个东西的误判恢复过来。。。
就算重复上面的过程,继续压榨非法单词的数目出来的更新的变换规则,频数前三也轮不到这仨货。。。。
后来又看了一下最上面的柱状图。。。统计了一下字母出现频率里面这三个字母出现的总频率,额。。。。
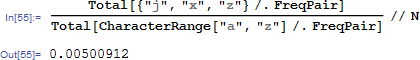
所以。。。我放弃了。。。因为现在这个解密规则下,已经基本可以通读全文了。。除非你原本就不认识那个单词。。。
以上!!
【完】
本文内容遵从CC版权协议,转载请注明出自http://www.kylen314.com

不错!涨姿势了
我都觉得这篇已经到了没人看的地步了。。
霸气的“以上!!”有种知乎范,哈哈
日剧动漫看多了的综合症。。
啊啊啊啊啊 最近安全学作业要做这个 找资料找到这里来了 博文都挺有意思 博主加油哦~~
看上去很不错的量化破解古典密码的工具呢~顶一个!顺便我这边还有几篇类似的密文,博主有没有兴趣拿来验证一下这种方法的适用性呢哈哈