Scrapy+Mathematica制作神奇宝贝图鉴书签
话说最近不是那个神奇宝贝起源开播了么?呀呀呀呀,真是的,那个BGM,那个剧情走向,真是让人把持不住啊。。。
加上之前学Python和Scrapy,很想找个什么东西来练练手,所以就决定了题目所说的那个”企划”,事实证明,这个东西其实一天就可以解决了。。。下面就是制作出来的成果啦~
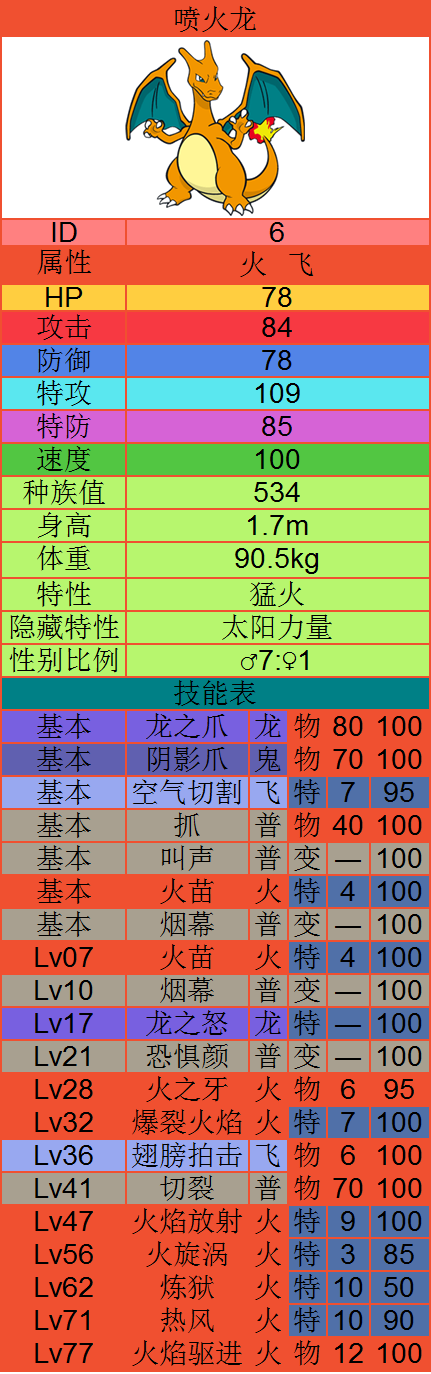
下面是制作过程,唉,管这个叫做制作过程,说的好像很手工很苦力似的,其实完全编程实现,苦力没有,全他喵的是脑力活。。。当然某种意义上,一直编程也算苦力活吧。。。
爬虫:
首先,就是要获取到那些数据,怎么获取,从一个叫做口袋百科的地方去”偷”,上面有所有的神奇宝贝的数据,但是我们只要抓取我们感兴趣的就可以了,先找到一个包含所有宝贝的链接的页面,作为爬虫的起始页面,就决定是你了!!http://www.pokemon.name/wiki/%E7%B2%BE%E7%81%B5%E5%88%97%E8%A1%A8;
查看上面那个页面的源文件,可以看到所有的宝贝的链接都非常整齐,看到这种源文件一般都是心情不能愉悦更多的!!
<table class="graytable"> <tr> <th colspan="2"> 关东地区 </th></tr> <tr> <td> 001 </td> <td> <a href="/wiki/%E5%A6%99%E8%9B%99%E7%A7%8D%E5%AD%90" title="妙蛙种子">妙蛙种子</a> </td></tr> <tr> <td> 002 </td> <td> <a href="/wiki/%E5%A6%99%E8%9B%99%E8%8D%89" title="妙蛙草">妙蛙草</a> </td></tr> <tr> <td> 003 </td> <td> <a href="/wiki/%E5%A6%99%E8%9B%99%E8%8A%B1" title="妙蛙花">妙蛙花</a> </td></tr> <tr> <td> 004 </td> <td> <a href="/wiki/%E5%B0%8F%E7%81%AB%E9%BE%99" title="小火龙">小火龙</a> </td></tr> <tr> <td> 005 </td> <td> <a href="/wiki/%E7%81%AB%E6%81%90%E9%BE%99" title="火恐龙">火恐龙</a> </td></tr> <tr> <td> 006 </td> <td> <a href="/wiki/%E5%96%B7%E7%81%AB%E9%BE%99" title="喷火龙">喷火龙</a>
所以要定位每个宝贝的名字,编号,还有页面链接就可以直接:
PokemonNumbers = hxs.select("//tr/td[1]/text()").extract()
PokemonNames = hxs.select("//tr/td[2]/a/text()").extract()
PokemonLinks = hxs.select("//tr/td[2]/a/@href").extract()
虽然我们这里真正需要的只有链接一个而已。。。然后下一步就是向每个页面深处我们的魔爪——把链接全部加入爬虫队列:
for i in range(1,len(PokemonNumbers)): PokemonLinks[i] = 'http://www.pokemon.name'+PokemonLinks[i] r = Request(PokemonLinks[i], callback=self.parse_GetPokemon_Detail) req.append(r) return req
然后就是到每个页面去找我们需要的信息了,代码全部写在函数parse_GetPokemon_Detail里面,这里我集中说一下几个会出现的麻烦事儿,一个是编码问题,页面里面很多中文,但是scrapy默认编码下得到的全部回事乱码,所以需要在开头:import sys,然后用下面两行改一下:
reload(sys)?
sys.setdefaultencoding(‘utf-8’)?
其次就是每个页面里面的数据的分布其实很不规则,完全没有第一个引导页面那个整洁。。。。
因为!!!他喵的,400号后面的新出的很多新的神奇宝贝,尼马各种形态,然后不同形态还有不同的技能树,还有什么陆地状态天空状态,不同状态下尼马种族值还不一样,然后,就是因为种种变化,技能表里面有些字是斜体的,有些是粗体的,这几个问题发现就花了我不少时间,还要找一个很好的XPath表达式唯一定位到我想要的东西,基本所有的时间都花在这些地方了!!【气死我了。。。。】
好,冷静一下,所以对于你想要的信息,你所需要的就是定位出它的位置,好,我决定一句话带过了。。。
之后的东西就完全没什么技术含量了,代码直接扔最下面了。。。【哦,对了,抓取数据要注意一下时间间隔,不然,返回来的结果会很糟糕,我曾试过649个神奇宝贝只拿回来421个的数据。。我是间隔留了1秒,然后人跑去吃饭,回来就数据全部拿回来了。。】
反正,我最后要得到的东西就是两个,一个是每个神奇宝贝的图片,在每个宝贝的页面定位到他们的链接地址,直接用代码把它们下载下来,另一个是文本txt,里面包含我想要的信息,我最后搞出来的就是这个样子的:
喷火龙 ID 006 Attribution 火 飞 HP 78 Att 84 Def 78 Spe_Att 109 Spe_Def 85 Speech 100 Sum 534 Heigth 1.7m Weigth 90.5kg Feacture 猛火 Hide_Feacture 太阳力量 Gender ♂7:♀1 ImageLink http://www.pokemon.name/w/image/Sprites/PDW/006.png 基本 龙之爪 龙 物 80 100 基本 阴影爪 鬼 物 70 100 基本 空气切割 飞 特 7 95 基本 抓 普 物 40 100 基本 叫声 普 变 ― 100 基本 火苗 火 特 4 100 基本 烟幕 普 变 ― 100 Lv07 火苗 火 特 4 100 Lv10 烟幕 普 变 ― 100 Lv17 龙之怒 龙 特 ― 100 Lv21 恐惧颜 普 变 ― 100 Lv28 火之牙 火 物 6 95 Lv32 爆裂火焰 火 特 7 100 Lv36 翅膀拍击 飞 物 6 100 Lv41 切裂 普 物 70 100 Lv47 火焰放射 火 特 9 100 Lv56 火旋涡 火 特 3 85 Lv62 炼狱 火 特 10 50 Lv71 热风 火 特 10 90 Lv77 火焰驱进 火 物 12 100
Mathematica制作:
其实mathematica制作这个过程,应该用别的软件做的,比如C++之类的,但是,因为我就是想用mathematica做,怎样!!主要是我很喜欢”玩弄”Mathematica啦。。。
Mathematica主要就是几个问题,一个是因为爬虫的数据文本文件里面,神奇宝贝的排序并不是顺序的,是按照返回的包的顺序,所以你想输出某个特定的神奇宝贝的图鉴,还需要定位一下他所在文本中的位置。。
其次一个问题就是第一次发现的,读取带有中文的文件,需要改一下Import函数的编码方式。。。
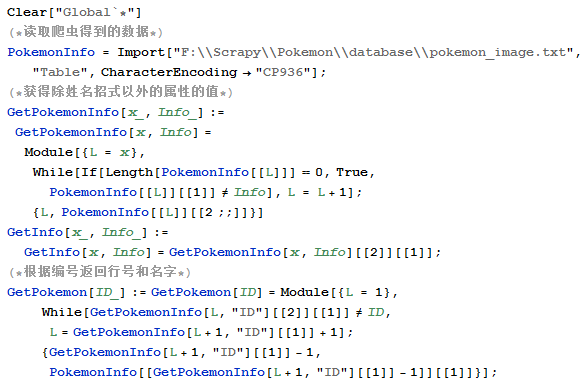
mathematica code
然后就是为了可以更加灵活的编排每个格子的信息,最好就是采用表格嵌套表格的方法,所以也需要写一个拼接表格的函数:

mathematica code
第三个方面就是技能表,唉,因为不像其他信息一样是固定长度的,所以需要为技能表专门写一写函数,获取技能的信息,技能的种类什么的。。。

mathematica code
有了上面的准备工作,表格的输出就很方便了。。代码看起来也很简洁,工整。。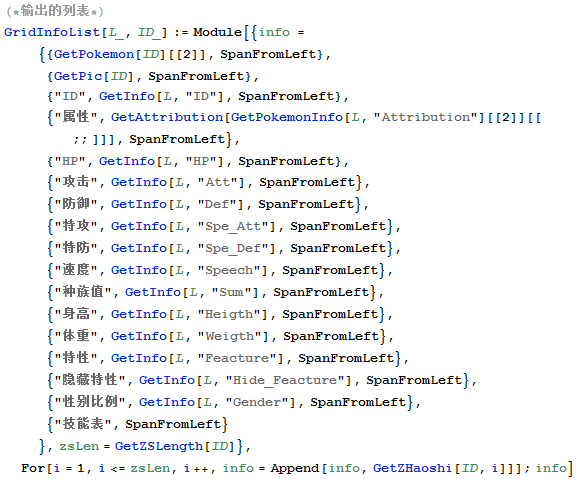
mathematica code
但是,仅仅是这样自然是不够的,因为不够美观,为了美观,我们需要給格子弄上背景颜色,但是为了符合神奇宝贝的特性,颜色我们应该根据他们的属性来选取,所以就需要做一个配色方案。。
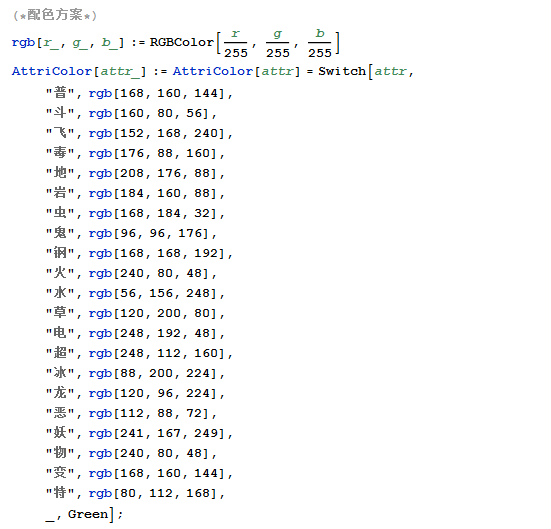

mathematica code
最后的输出就没什么技术含量了。。。

mathematica code
想要输出谁的图鉴,只要一行语句就可以了。。
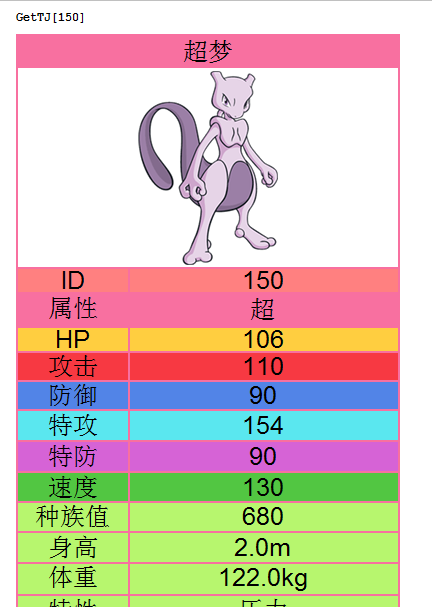 好,以上!!
好,以上!!下面给上又长又臭的爬虫代码。。。
爬虫代码:
from scrapy.spider import BaseSpider
from scrapy.selector import HtmlXPathSelector
from scrapy.http import Request
from scrapy.conf import settings
import time
import sys
class Pokemon(BaseSpider):
name = "Pokemon"
f = open('pokemon_base_info.txt','wb');
f_image = open('pokemon_image.txt','wb');
start_urls = ["http://www.pokemon.name/wiki/%E7%B2%BE%E7%81%B5%E5%88%97%E8%A1%A8"];
download_delay = 1
def parse(self, response):
reload(sys) # 2
sys.setdefaultencoding('utf-8') # 3
req = []
hxs = HtmlXPathSelector(response)
PokemonNumbers = hxs.select("//tr/td[1]/text()").extract()
PokemonNames = hxs.select("//tr/td[2]/a/text()").extract()
PokemonLinks = hxs.select("//tr/td[2]/a/@href").extract()
PokemonNumbers = PokemonNumbers[4:];
PokemonNames = PokemonNames[1:];
PokemonLinks = PokemonLinks[3:];
for i in range(1,len(PokemonNumbers)):
self.f.write(PokemonNumbers[i])
self.f.write(':')
self.f.write(PokemonNames[i])
self.f.write(':')
PokemonLinks[i] = 'http://www.pokemon.name'+PokemonLinks[i]
self.f.write(PokemonLinks[i])
self.f.write('\r\n')
r = Request(PokemonLinks[i], callback=self.parse_GetPokemon_Detail)
req.append(r)
return req
def parse_GetPokemon_Detail(self, response):
reload(sys) # 2
sys.setdefaultencoding('utf-8') # 3
req = []
hxs = HtmlXPathSelector(response)
image = hxs.select("//table[1]/tr/td[1]/img[1]/@src").extract()
name = hxs.select("//table/tr/th/div[3]/text()").extract()
shuxing = hxs.select("//table/tr/td/a[@href='/wiki/%E5%B1%9E%E6%80%A7']/parent::*/following-sibling::*/a/text()").extract();
id = hxs.select("//table/tr/td/a[@href='/wiki/%E5%85%A8%E5%9B%BD%E5%9B%BE%E9%89%B4']/parent::*/following-sibling::*/b/text()").extract()
heigth = hxs.select("//table/tr/td/a[@href='/wiki/%E8%BA%AB%E9%AB%98']/parent::*/following-sibling::*/text()").extract();
weigth = hxs.select("//table/tr/td/a[@href='/wiki/%E4%BD%93%E9%87%8D']/parent::*/following-sibling::*/text()").extract();
feacture = hxs.select("//table/tr/td/a[@href='/wiki/%E7%89%B9%E6%80%A7']/parent::*/following-sibling::*/a/text()").extract();
hide_feacture = hxs.select("//table/tr/td/a[@href='/wiki/%E9%9A%90%E8%97%8F%E7%89%B9%E6%80%A7']/parent::*/following-sibling::*//text()").extract();
gender = hxs.select("//table/tr/td/a[@href='/wiki/%E6%80%A7%E5%88%AB']/parent::*/following-sibling::*/text()").extract();
power_idx = hxs.select("//h3/span[@id='.E7.A7.8D.E6.97.8F.E5.80.BC']/parent::*/following-sibling::*//dd//td[1]/text()").extract()
zhaoshi = hxs.select("//table[@style='text-align:center;float:left;white-space:nowrap;margin:auto 0.2em 0.2em auto'][1]/tr").extract();
print '-----------------------------',name[0],'------------------------'
self.f_image.write(name[0])
self.f_image.write("\r\nID:")
self.f_image.write(id[0])
self.f_image.write("\r\nAttribution:")
for i in range(len(shuxing)):
self.f_image.write(shuxing[i])
self.f_image.write(' ')
self.f_image.write('\r\nHP:')
self.f_image.write(power_idx[0])
self.f_image.write('Att:')
self.f_image.write(power_idx[1])
self.f_image.write('Def:')
self.f_image.write(power_idx[2])
self.f_image.write('Spe_Att:')
self.f_image.write(power_idx[3])
self.f_image.write('Spe_Def:')
self.f_image.write(power_idx[4])
self.f_image.write('Speech:')
self.f_image.write(power_idx[5])
self.f_image.write('Sum:')
self.f_image.write(power_idx[6])
self.f_image.write('Heigth:')
self.f_image.write(heigth[0])
self.f_image.write('\r\nWeigth:')
self.f_image.write(weigth[0])
self.f_image.write('\r\nFeacture:')
self.f_image.write(feacture[0])
self.f_image.write('\r\nHide_Feacture:')
self.f_image.write(hide_feacture[0])
self.f_image.write('\r\nGender rate:')
self.f_image.write(gender[0])
self.f_image.write('\r\n');
self.f_image.write('Image Link:')
self.f_image.write(image[0])
for i in range(2,len(zhaoshi)+1):
zs = hxs.select("//table[@style='text-align:center;float:left;white-space:nowrap;margin:auto 0.2em 0.2em auto'][1]/tr["+str(i)+"]/td//text()").extract()
if(zs == []):
break
while(u'\n' in zs):
zs.remove(u'\n')
zs_name = hxs.select("//table[@style='text-align:center;float:left;white-space:nowrap;margin:auto 0.2em 0.2em auto'][1]/tr["+str(i)+"]/td/a/text()").extract()
self.f_image.write(zs[0][:-1]+" ")
self.f_image.write(zs_name[0]+" ")
self.f_image.write(zs[2][:-1]+" ")
self.f_image.write(zs[3][:-1]+" ")
self.f_image.write(zs[4][:-1]+" ")
self.f_image.write(zs[5][:-1]+"\r\n")
self.f_image.write('\r\n\r\n')
r = Request(image[0], callback=self.parse_GetPokemon_Image)
req.append(r)
return req
def parse_GetPokemon_Image(self, response):
str = response.url;
str = str.split('/');
imgfile = open(str[-1],'wb')
imgfile.write(response.body)
print '--------------image---------------',str[-1],'------------------------'
【完】
本文内容遵从CC版权协议,转载请注明出自http://www.kylen314.com

{kind=link}
今天爬了下搜狗视频的网页,发现下一页的网址和上一页的网址是一样的,这样的话我怎么去爬下一页呢?这个是地址:http://v.sogou.com/v?query=%CE%A2%D0%C5&typemask=6&p=&dp=&w=06009900&_asf=v.sogou.com&_ast=1387529246&dr=&enter=1&sut=6410&sst0=1387529261714
他是调用了JS文件返回下一页的地址的,你要去看他那个JS文件的代码,然后去找Scrapy怎么调用JS函数的方法
恩恩,下次要去研究下scrapy怎么解析JS文件了。还有个问题要问下你,scrapy的start_urls中可以放多个站点,但是如果每个站点的结构完全都不一样,那就不能都放在一个parse函数中解析吧,可是start_urls中url默认回调函数是parse,那该怎么做呢?
爬JS用WEBKIT;一种简单的思路就是写多个类从BaseSpider继承下来;或者你可以尝试一下parse为空,然后直接在设置start_urls那里append新的request指定回调函数看一下行不行。。我没试过,感觉应该是可以的。。
提些小建议:1、对于路径,”\”可以用”/”代替。估计你是直接复制粘贴的路径。2、对于延迟计算“:=”,后面没有必要把函数名再重新写一遍。★ 如果可以,想和你交换个链接。我的博客:闲云谷★ 我在人大经济论坛新开设了一个Mathematica版块,欢迎加入
1.是的。。而且一般路径比较深,改起来麻烦。。反正Mma自己会转,又不影响可读性,所以我一般也不管。。2.那个是Mma的惰性编程,这么做的话,越往后面输出速度可以越来越快。不然根本做不到秒出一张图。。。★可以啊,但是怎么好像你博客打不开。。。不会又是这边校园网的问题吧。。。orz。。
那个版块是这个?http://bbs.pinggu.org/forum-164-1.html
嗯。是那个版块。刚刚开始做。我也是个Mathematica爱好者,嘻嘻……我那个博客刚刚开通两个月,一直都可以正常打开的。也是租的香泽的服务器。贴个地址吧:http://xianyungu.com
居然加了友链就可以打开了。。。囧。。。
手机gprs测试了一下,你博客打得开。。看来是校园网问题。。。友链已添加。
前两天无聊,我试着给10086发信息:“我想你了。”
没想到10086真的给回信息了:“那就来找我嘛,死鬼!”
然后我吓得赶紧放下了爸爸的手机。
很久没来了,过来看看